Искусственный интеллект и будущее разработки программного обеспечения. Human after all
2026-ый год наступил. 2 волны сокращений прожиты. Как мы пришли к текущей точке? Что меняется уже сегодня и какие сценарии развития наиболее правдоподобны?
Эта работа есть результат моей практической и теоретической работы которая выходит за пределы одного года. Впервые её основу я продемонстрировал летом 2025-го. Когда она оформилась в текст я не понимал что это - эссе, инструкция, пост, статья или что-то другое
Только в день публикации я понял, что это песня акына в которой есть лейтмотивы - качество, адаптация, профессионализм

Мы на пороге крупных перемен в том, что касается создания программного обеспечения. Кажется, еще немного — и нейросети сами будут писать код, а профессия разработчика радикально изменится. Одни тексты пугают: мол, «программистов заменят ИИ», другие, напротив, безудержно вдохновляют. Реальность же, как обычно, сложнее и интереснее. В этой работе я попытаюсь трезво и практически взглянуть на воздействие искусственного интеллекта на разработку: как мы пришли к текущей точке, что уже меняется сегодня и какие сценарии будущего наиболее правдоподобны. Вместо громких лозунгов будет разбор с опорой на исследования и практику, а итогом — конкретные модели, принципы и дорожные карты действий для инженеров разных уровней и специализаций
Для кого эта статья? Для всех, кто вовлечен в разработку ПО: от intern/junior инженеров до senior/lead; для всех направлений – front-end, back-end, DevOps/SRE, QA, design, system analysis; для тимлидов и руководителей, которые хотят удержать качество продукта при ускорении процессов
Что ты получишь на выходе? Приблизительную картину индустрии: прошлое -> настоящее -> гипотезы будущего; моё понимание модели SE 3.0 – «намерение -> генерация -> верификация -> поставка» (концепция, которая за последний год завоевала умы многих корпоративных визионеров. Источник концепции); практические дорожные карты развития:
- по грейдам инженеров (от intern до lead)
- по стримам (FE/BE/DevOps/QA/Design/SA)
а также набор план действий на 30/90/365 дней для инженера, лида и компании.
Маршрут чтения
- если у тебя 10 минут, прочитай Пролог -> SE 3.0 (конвейер и гейты) -> План 30/90/365 – этого хватит, чтобы уловить суть
- за 30–40 минут добавь главы Термины и границы -> Где мы сейчас (практики и риски) -> Дорожные карты по грейдам
- полный разбор (2–3 часа) включает историческую часть, чтобы понять, почему простое "ускорение" без дисциплины почти всегда ломает качество
ИИ — не замена программиста, а ускоритель производства. А любой ускоритель делает два дела одновременно: увеличивает скорость выпуска ценности и повышает цену ошибки если у тебя не выстроены верификация и дисциплина. Ускоряться безопасно могут только те команды, у которых сильны тормоза (автотесты, мониторинг) и руль (четкие спецификации и процессы)
Термины и рамки
Прежде чем двигаться дальше, уточню терминологию — это важно, чтобы нам говорить на одном языке
Kickback— это скрытое вознаграждение (откат), которое получает человек, принимающий решение, за выбор конкретного инструмента/подрядчика, даже если этот выбор вреден для проектаSDLC (Software Development Life Cycle)— жизненный цикл разработки ПО: требования -> дизайн -> реализация -> тестирование -> релиз -> эксплуатация -> улучшения. Это полный процесс «от идеи до работающей системы».Golden path— «проторенная дорожка», стандартизованный и поддерживаемый способ решать типовые задачи в организации (платформенные шаблоны, гайдлайны и т.п.), благодаря которому правильное решение сделать проще всего. (Примеры: внутренние гайдлайны Spotify Engineering, обзор концепции Golden Paths от Red Hat)Triage— первичная сортировка и разбор входящих проблем (тикетов, баг-репортов, алертов). Термин из медицины: необходимо быстро определить приоритет, ответственного и следующий шаг по каждой новой проблеме. В разработке это аналогично: понять, что случилось, насколько срочно, кому поручить и что делать сначала (. См. пример: Atlassian — Bug triage)ИИ в разработке (AI-assisted development)— применение ML-моделей и агентных систем для ускорения выполнения задач вSDLC: от анализа требований и прототипирования до написания кода, тестирования, код-ревью, отладки и поддержки. Речь о любой помощи со стороны ИИ-инструментов в процессе разработкиLLM (Large Language Model)— большая языковая модель, обученная на массиве текстовых (и не только) данных. По сути, работает как вероятностный компилятор намерений: умеет превращать запросы на естественном языке (или на псевдокоде) в осмысленные продолжения (текст, код, картинки и тд), обобщая паттерны из тренировочного корпуса- Модели
on-prem— это модели, которые разворачиваются и работают на инфраструктуре самой компании, а не в публичном облаке провайдера. Данные и вычисления не покидают периметр организации Ассистент / Copilot-режим— сценарий взаимодействия «человек ведет, модель подсказывает». Например, автодополнение кода, генерация отдельных фрагментов по запросу, объяснения к существующему коду, предложения по улучшению. Разработчик контролирует процесс, ИИ экономит время на рутинеАгент— сценарий «модель действует сама». ИИ получает задачу на высоком уровне и самостоятельно планирует шаги: может вызывать инструменты (запросы к репозиторию, запуск тестов, линтеров, выполнение поиска по документации), писать и переписывать код итеративно, пока не достигнет цели. Агент — это не магия и не самосознание, это «LLM + инструменты + цикл контроля результата». Он тоже делает ошибки, и ему нужны ограничения (ограждения) и проверкиVibeCoding— подход к разработке в режиме непрерывного диалога с моделью: «сформулируй намерение -> сгенерируй -> подправь» — с минимальным ручным планированием заранее. Отлично ускоряет получение прототипа или MVP, но опасен для долгоживущих систем без должного контроля качества, ибо велик риск быстро нагенерировать технический долг и ошибкиSE 1.0 / SE 2.0 / SE 3.0— условные "эпохи" индустрии разработкиSE 1.0– ручное производство софта и ручная же проверка качества. Проекты зависят от индивидуальных героев: если сильный разработчик ушёл, половина знаний уходит вместе с нимSE 2.0– индустриализация разработки. Появление CI/CD, автоматизации тестирования, практик DevOps и Observability. Поставка изменений (deployment) стала поставлена "на рельсы" – непрерывные интеграция и развертывание, инфраструктура как код, мониторинг на проде. Больше системности: качество меньше зависит от героизма, больше – от процесса.SE 3.0– зарождающаяся сейчас парадигма: производство фич в связке «человек формулирует намерение и критерии -> системы генерируют реализацию -> системы проверяют качество -> человек принимает итоговую ответственность». Идея в том, что участие ИИ становится частью ядра процесса разработки, а не просто плагином "для удобства".
Инварианты- это неизменяемые правила корректности системы, которые должны оставаться истинными всегда (или в оговорённых состояниях), независимо от того, кто и как менял код — человек или ИИ. Это "законы физики" твоего домена, на которых строится проверка. Тесты могут быть "кейсами", а инварианты — "аксиомами". Типичные классы инвариантов с примерами- Доменные (бизнес) инварианты
- оплаченный заказ не может стать неоплаченным без операции возврата
- сумма позиций заказа = итого по чеку
- лимит карты не может быть меньше текущей задолженности
- Инварианты данных
- уникальность (email уникален)
- ссылочная целостность (order -> customer существует)
- диапазоны ("цена ≥ 0", "скидка 0..100%")
- согласованность ("createdAt ≤ updatedAt")
- Инварианты состояния
- допустимые переходы статусов: NEW -> PAID -> SHIPPED, но не NEW -> SHIPPED
- инцидент не может быть CLOSED, если нет RCA/постмортема
- Инварианты интерфейсов/контрактов
- этот API всегда возвращает id и status, а status только из enum
- событие в шине имеет схему версии N; несовместимые изменения запрещены
- Инварианты безопасности
- нельзя выдать роль admin через публичный endpoint
- секреты не попадают в логи
- Доменные (бизнес) инварианты
Где инварианты можно встретить в реальном проекте
- в типах (
TypeScript/Java/Kotlin): ограничение состояний черезтипы/enum/ADT - в коде домена: проверки/guards в сущностях/агрегатах
- в БД:
NOTNULL,CHECK,UNIQUE,FOREIGN KEY - в контрактах:
OpenAPI/JSON Schema/Proto+contract tests - в тестах свойств:
property-based testing(генерируем много входов и проверяем инвариант) - в рантайме:
asserts/валидаторы + наблюдаемость ("если инвариант нарушен — алёрт")
Инварианты — это как раз "что значит корректно" в форме, которую можно проверять автоматически
То, данное видео лучше всего раскроет суть инварианта для большинства инженеров
Эти термины буду использовать далее по тексту
Уроки истории. Эволюция разработки и абстракций
История разработки ПО знает несколько витков повышения абстракции. Каждый раз звучало, что вот теперь-то писать код станет проще или вообще будет не нужно, но каждый раз происходило не исчезновение программистов, а расширение возможностей индустрии, расширение стека и ... увеличение числа программистов потому, что барьер входа снижался, а спрос продолжал предъявляться
Давай кратко проследим эти вехи, чтобы понять контекст нынешнего "ИИ-буума"
1940–50е. ENIAC / Ранняя инженерия

Программирование было физическим занятием – перетыкание переключателей, перекоммутация проводов, перфокарты. Чтобы "изменить программу", инженеру буквально приходилось менять конфигурацию машины. Бутылочным горлышком была скорость человеческих операций и отсутствие автоматизации – люди тормозили машины. Ошибки возникали из-за сложности удержать все нюансы в голове, повторяемость процессов отсутствовала. Программисты тогда – скорее техники, напрямую работающие с железом
1960–70е. Языки высокого уровня и массовый кодинг

Появились языки программирования (Fortran, Basic, C и пр), благодаря которым «писать программу» стало означать писать текст, а не руками настраивать оборудование. Порог входа в кодинг резко снизился – сотни тысяч людей смогли создавать софт, индустрия выросла. Однако новым бутылочным горлышком стали качество и дисциплина: код писали многие, но далеко не всегда хорошо; возникла потребность в стандартах, тестировании, методологиях, чтобы избежать хаоса
1980–90е. Сложные системы

Создание системного ПО, переносимость кода между разными машинами – всё это выросло из языка C (Деннис Ритчи и др) и культуры UNIX. Началась индустриализация сложных проектов: операционные системы, сети, базы данных, большие энтерпрайз-приложения. Команды выросли, компоненты должны были работать вместе. Главным вызовом стало управление сложностью: требовалась архитектура, продуманные дизайны, борьба с утечками памяти, умение сопровождать систему годами. Появляется понимание «software engineering» как дисциплины
2000–е. Интернет и масштабирование

С приходом веба и глобальных сетей программирование стало социальным видом деятельности. Множество команд и сервисов должны взаимодействовать по API, соблюдать контракты совместимости, постоянно интегрироваться. Сценарии отказов стали сложнее: теперь баг в одном микросервисе мог обрушить целый продукт, в систему пришли миллионы пользователей. Цена ошибки возросла, а факторы сложности сместились в интеграцию, сетевые задержки, отказоустойчивость, наблюдаемость. Нужно отслеживать, как изменение в коде отражается на всей распределенной системе
2010–е. DevOps, облака, CI/CD

Возникла культура, где разработка включает не только написание кода, но и поставку/эксплуатацию. DevOps связал разработчиков и операционщиков, облачные платформы убрали многие инфраструктурные барьеры. Код деплоится постоянно, релиз стал «не событием, а непрерывным процессом». Это дало гигантский выигрыш в скорости, но поставило задачу: как удержать качество на этой скорости? Появились автоматизированные тесты, сложные пайплайны сборки, практики безопасности цепочки поставок. Узким местом стало именно качество при высокой скорости изменений. Не случайно, если в организации внедрили CI/CD без адекватных quality gates, начинался всплеск инцидентов
2010–20е. Low-code / No-code волны

Каждые несколько лет появлялись конструкторы и платформы, обещавшие: «Теперь-то уж кодить не придется – бизнес-аналитики сами "накликают" себе приложение». Отчасти это сбылось для простых задач: часть типовой работы ушла на платформы вроде WordPress, Airtable, конструктора мобильных приложений и тп. Но вместо конца профессии это привело к новым ролям: интеграторы, архитекторы, платформенные команды, Data Engineering, специалисты по безопасности – словом, люди, которые отвечают за несервисные аспекты. Low-code инструменты хороши в своем домене, но их границы ограничены: если стоит задача выйти за рамки шаблона – снова нужен разработчик. Главный вывод: каждая новая абстракция снижает порог входа и ускоряет типовые решения, но переносит сложность на уровень контекста, интеграций, качества и ответственности
Каждый такой виток приводил не к исчезновению программистов, а к росту требований к ним. Когда что-то рутинное автоматизируется, возникают новые "сложные" задачи вокруг. Скажем, после low-code бумов стало еще важнее тщательно прорабатывать нестандартные кейсы, поддерживать платформы и разрабатывать интеграции
Почему же сейчас вопрос звучит особенно остро? Дело в том, что ИИ впервые претендует не просто на роль очередного «конструктора для типовых задач», а на генерацию осмысленного нового контента: кода, тестов, документации, конфигураций – того, что раньше создавалось человеком «с нуля». По сути, это новый скачок абстракции: разработчик может не писать вручную часть артефактов, а поручить модели. Однако есть ключевое отличие от прошлых эпох: скорость генерации выросла в разы, а вот проверка и интеграция результатов всё еще требуют труда. Мы получили "ускоритель" без эквивалентного "усилителя тормозов" – и это накладывает особые требования к культуре и процессам
Раньше автоматизация устраняла физический ручной труд (перфокарты -> компиляторы, ручной деплой -> CI/CD и тд). Теперь же автоматизация убирает ручное написание и даже обдумывание кода, но не убирает необходимость ручной ответственности и проверки. Эти последние – проверки, ревью, контроль качества – наоборот, становятся ещё важнее и дороже, потому что без них ускоренная генерация быстро превратится в ускоренное производство багов
Эволюция процессов. От Waterfall до AI-помощников
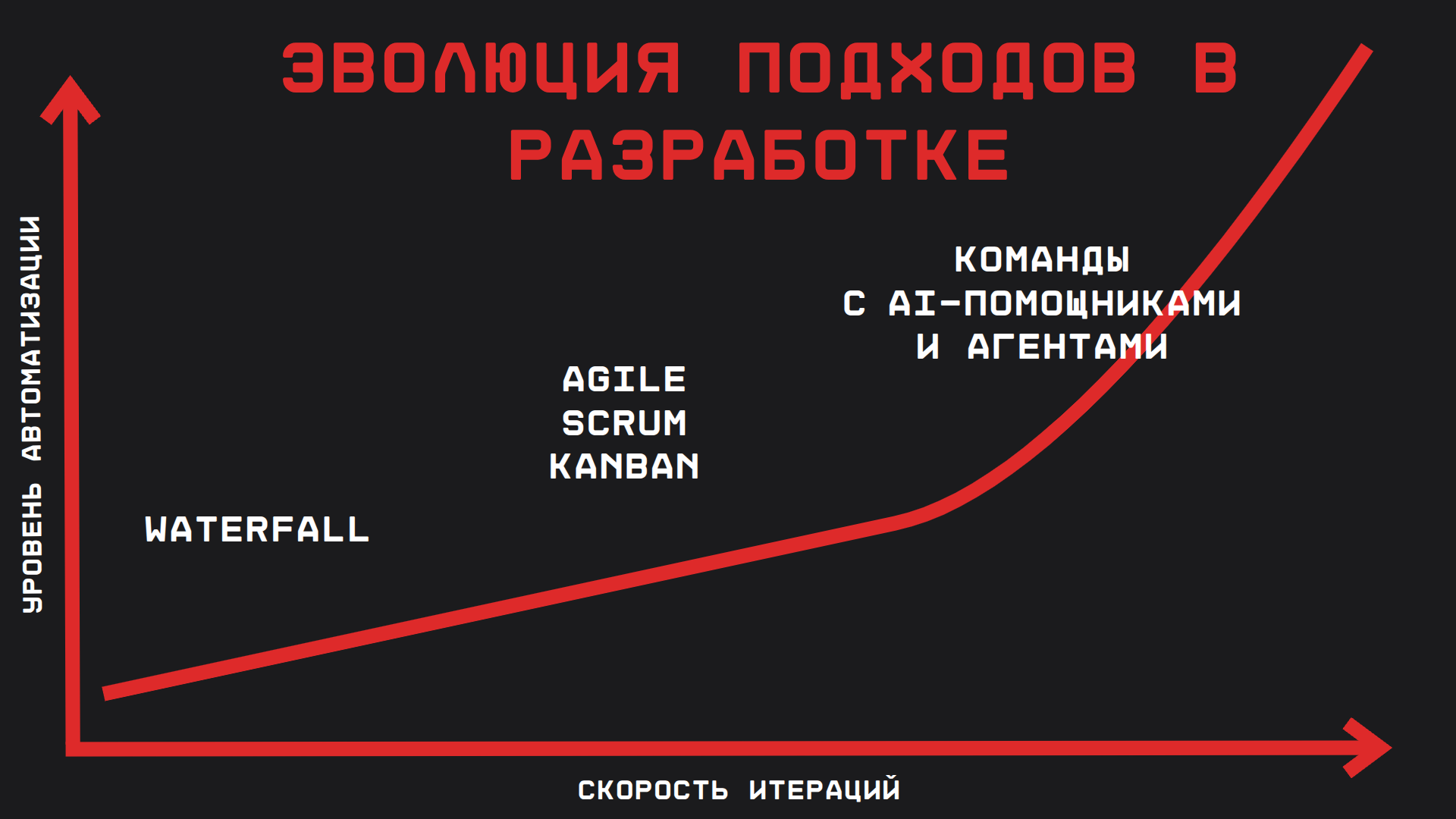
Помимо уровня абстракций в коде, история развития ПО – это ещё и эволюция процессов управления разработкой. Каждый шаг здесь также связан с ускорением обратной связи и контролем качества на новом уровне. Вспомним вкратце
- Waterfall (классический каскадный подход). Контроль через детальный план. Требования собираются разом, затем месяцы пишется код, потом тестирование и внедрение. Сильная сторона – подходит для стабильных доменов с чёткими требованиями и средой без изменений. Главный минус – очень поздняя обратная связь: ошибка, допущенная в начале, обнаруживается в конце проекта, когда всё уже собрано. Типичная боль – «мы сделали всё по плану, но это не то, что было нужно». Жизненный цикл длинный, изменения в требованиях плохо переносит
- Agile / Scrum / Kanban. Контроль через короткие итерации. Работу разбивают на спринты 1–4 недели, требования обновляются динамически, продукт часто демонстрируется. Сильная сторона – быстрая обратная связь от пользователей, адаптация к изменениям. Слабость – если нет должных инженерных практик,
Agileлегко превращается в «бесконечную суету»: фичи клепаются, но долгосрочное качество или архитектура страдают. Часто наблюдаем: команда быстро пилит функциональность, но через пару лет система деградирует – её приходится переписывать из-за неустранимого техдолга. Причина: скорость без дисциплины - DevOps. Контроль через конвейер и совместную ответственность разработки и эксплуатации. Код не "перекидывается через забор" в отдел администраторов, а сразу думается с учетом деплоя и поддержки. Сила – выстроенные пайплайны доставки, инфраструктура как код, мониторинг и быстрота реакции на инциденты. Слабость – требует высокой зрелости: инструментов, культуры, навыков автоматизации. Боль – «мы ускорили релизы, а инцидентов стало больше», если не настроены quality gates или они фиктивны.
DevOpsдал индустрии скорость, но одновременно повысил цену ошибок, требуя еще более автоматизированных проверок качества - Platform Engineering. Контроль через стандартизацию и самообслуживание. Идея – дать командам внутренние "платформенные продукты" и золотые дорожки (
golden paths), чтобы команды не изобретали велосипед в инфраструктуре, а получали готовые решения (шаблон сервиса,CI/CD pipeline, мониторинг "из коробки"). Сила – повышает эффективность: меньше времени тратится на настройку окружения, больше – на бизнес-логику. Слабость – риск бюрократии: платформа может навязывать «один правильный путь» там, где он не всем подходит. Боль – если платформенная команда не успевает за запросами, она сама превращается в узкое горлышко и тормозит разработки - Teams with AI-helpers (то, что происходит сейчас). Контроль через «ускорение + верификация». Командам доступны помощники-ИИ (такие как
GitHub Copilot,ChatGPT,Code Interpreterи пр) для ускорения рутинных задач. Сильная сторона – рутинный труд (написание шаблонного кода, документации, тестов) разгружается, инженеры могут делать больше за меньшее время. Слабость – резкий рост объема изменений: если раньше разработчик писал 100 строк кода в день, а с ИИ может генерировать 1000, то проверять эти изменения становится сложнее. Цена проверки возрастает нелинейно. Боль – «агент нагенерил столько кода, что никто не успел понять, что там происходит». Без новых подходов к контролю качества можно утонуть в потоке изменений
Agile и DevOps ускорили обратную связь, позволив быстрее реагировать на проблемы. ИИ-инструменты же ускоряют сами изменения – производство артефактов (кода, тестов). Логично, что фокус теперь смещается на дисциплину проверки этих изменений. Если раньше главным было наладить быстрый цикл отклика (собирать требования и фидбэк), то теперь главное – успеть проверить всё, что сгенерировали
Инструмент без процесса = ускоренный технический долг. Если ИИ ускоряет написание кода, а у тебя
- требования размытые
- тестов толком нет
- код-ревью делается "по диагонали"
- метрики дефектов или инцидентов игнорируются
- то вы просто зальете систему сырым кодом и сломаете качество пропорционально ускорению. Применяя ИИ в незрелом процессе, компания лишь ускоряет наступление проблем, а не решает их
Команды с сильными процессами извлекут из ИИ максимум пользы, потому что у них уже есть "амортизаторы" для высокого темпа
6. SE 1.0 -> SE 2.0. Индустриализация разработки
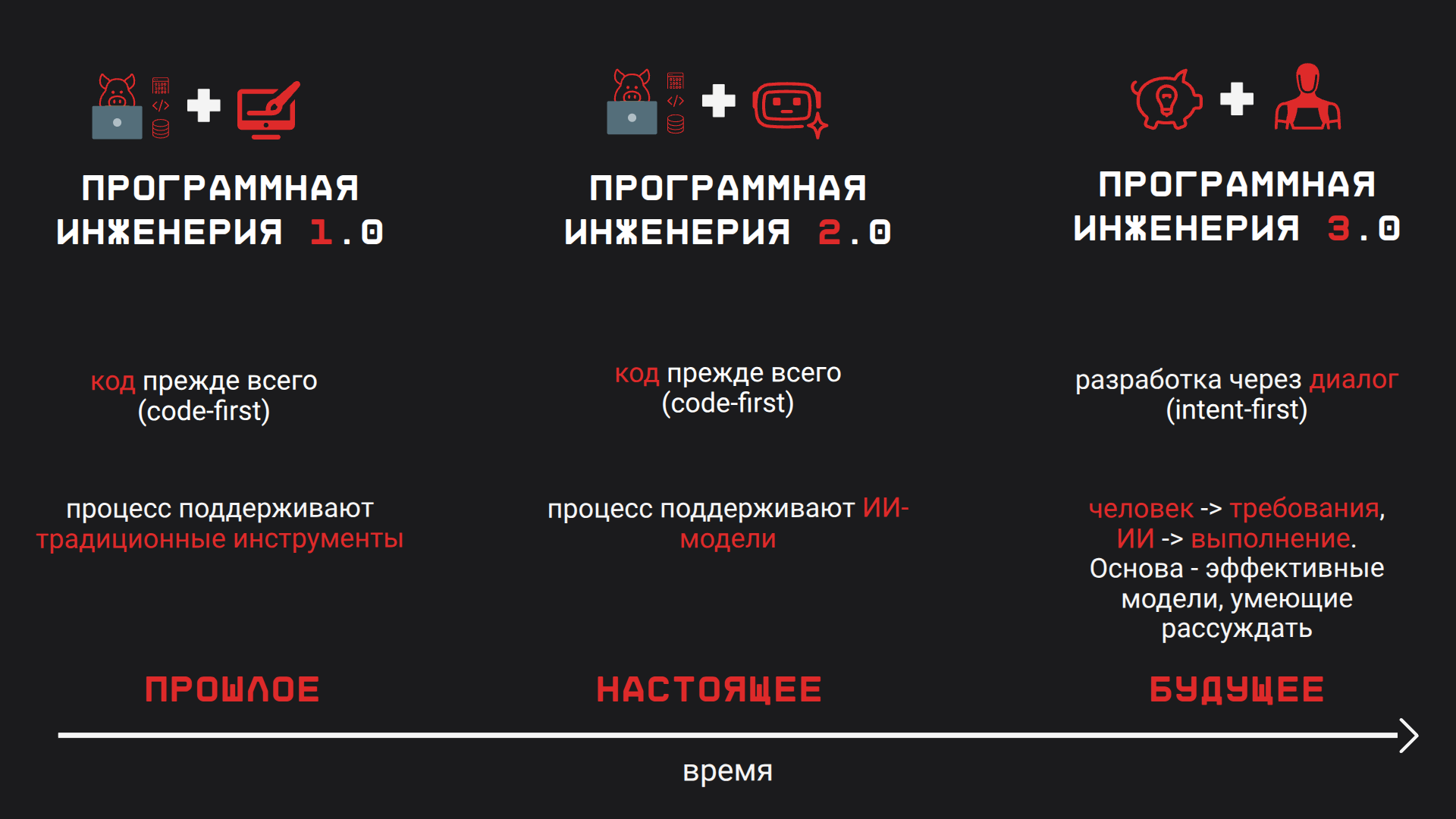
Чтобы понять, что такое SE 3.0, важно признать: мы уже живём не в "кодинге", а в промышленном производстве изменений. Разработка в этой парадигме становится диалогом про намерения, а код — результатом поиска по пространству решений. Инженер в этой парадигме есть оркестратор
SE 1.0 — производство вручную
- код пишется вручную, проверяется "глазами", поставка часто ручная
- качество держится на героях, знания живут в головах
- цена ошибки высокая, но скорость изменений ограничена
SE 2.0 — производство через конвейер
CI/CD, инфраструктура как код, автоматизация тестов, наблюдаемость- поставка становится повторяемой, измеримой, управляемой
- появляются новые "станки" производства: линтеры, статанализ, сканеры уязвимостей, policy-as-code, шаблоны сервисов, платформенные/процессные дорожки
- появляется ИИ как инструмент сбоку
Что стало дорогим в SE 2.0 и почему это важно для ИИ
1. Интеграции и зависимости
- мир стал API-ориентированным: ошибка в контракте = каскад (если ты из энтерпрайза ты меня понимаешь)
- изменения требуют координации, совместимости, миграций (и опять привет энтэрпрайзникам)
2. Качество и тестирование
- чем быстрее поток изменений, тем больше нужна автоматическая проверка
- тесты — не "долг" и не формальность, а страхование для скорости
3. Безопасность и поставка
- код — лишь часть системы; зависимости и пайплайны стали частью поверхности атаки
- безопасность не может быть "после релиза"
4. Наблюдаемость и эксплуатация
- если система не наблюдаема — она неуправляема
- ошибка без сигналов превращается в "охоту на призрака"
5. Распределённость команд и владение/ответственность Большие продукты живут в десятках команд а то и сотнях: успех зависит от границ ответственности и культуры взаимодействия
6. Copilotы
Нынешние copilotы (SE 2.0) действительно ускоряют рутинные куски, но оставляют разработчика "микроменеджером процесса" (человек всё равно тащит процесс целиком), создают когнитивную нагрузку и риск ошибок, и в целом не превращают разработку в "по-настоящему AI-native" процесс
SE 2.0 сделал разработку "конвейером". ИИ приходит не в вакуум — он встраивается в этот конвейер и начинает ускорять выпуск изменений. Следующий шаг — SE 3.0 — потребует перестроить верификацию изменений так же радикально, как SE 2.0 перестроил их поставку. Нужно не "сильное автодополнение кода", а другой процесс, где AI встроен в ядро, а не прикручен сбоку
Что было "ручным" и как стало в SE 2.0
| Область | SE 1.0 (вручную) | SE 2.0 (индустриально) | Что станет критично при ИИ |
|---|---|---|---|
| Сборка/релиз | ручные шаги | CI/CD | скорость без контроля = риск |
| Проверка | ручное тестирование | автотесты + линтеры | нужно больше и умнее верификации |
| Инфраструктура | "на серверах руками" | IaC, шаблоны | агентам нужны guardrails |
| Качество | "на опыте" | quality gates | политика и метрики качества |
| Эксплуатация | "по ощущениям" | observability | быстрый MTTR, объяснимость |
Где мы сейчас. Практика и драйверы изменений
Настоящее время в разработке примечательно тем, что крупные языковые модели стали доступны массово, и индустрия активно их пробует. Что же реально сдвинулось в процессах благодаря ИИ?
Ключевые драйверы, почему ИИ меняет разработку уже сегодня
- Качество современных LLM выросло. Если еще пару лет назад генерировать цельный модуль кода без ручной правки было сложно, то теперь передовые модели кодят на уровне линейного разработчика (в некоторых задачах). Это не значит, что они безошибочны – но они достаточно хороши, чтобы их стало выгодно использовать на реальных задачах. Даже если модель пишет с качеством 7/10 от человека, но делает это за секунды – в умелых руках это ускорение
- Снижение стоимости генерации. Запрос к API модели или локальный запуск стоит копейки по сравнению с часовыми ставками разработчиков. ИИ-инструменты быстро окупаются: с их помощью можно, например, сгенерировать сотни тестов или документацию за вечер – то, на что у команды ушли бы недели. Стартапы особенно выигрывают: они могут сделать больше с меньшими ресурсами
- Интеграция ИИ в привычные инструменты. Copilot в популярных IDE, чат-боты прямо в
VS Code, вGitLab CIи тд. ИИ стал частью рабочего окружения. Раньше, чтобы применить ML в кодинге, надо было быть энтузиастом и мастером скриптов, теперь же инструменты предлагают это "из коробки" – порог входа снизился. Происходит общее распространение практики: даже те, кто далек от машинного обучения, начали пользоваться готовыми ИИ-средствами - Конкуренция и хайп. Не будем отрицать человеческий фактор: все говорят об ИИ, и компании не хотят отставать. Менеджеры требуют "прикрутить AI" где можно, разработчики экспериментируют, чтобы быть в тренде. В какой-то мере это мода, но мода, подкрепленная реальными кейсами успеха: компании от
Microsoftдо маленьких стартапов рапортовали, что ускорили разработку и уменьшили баги с помощью ИИ-ассистентов. Это стимулирует остальных хотя бы попробовать... И мы пробуем - Новые возможности, которых раньше не было. Например, массовая миграция кода на новый фреймворк – раньше огромный ручной труд, а сейчас можно натравить на репозиторий агента, и он сам перепишет значительную часть, оставив человеку только проверить. Или генерация тестов по существующему коду: экономит дни работы. Таких качественно новых сценариев становится всё больше, и они показывают высокую эффективность на пилотах

Однако, при всех плюсах, важно понимать ограничения и риски текущего момента. Вот несколько наблюдений из практики
- ИИ ускоряет, но не мыслит как человек. Модели делают правдоподобный по форме код, но без понимания глубины. Отсюда – галлюцинации: модель уверенно пишет функцию, которая логически неверна или использует несуществующую сущность. Риски «уверенного бреда» особенно известны при генерации кода на уровне целых проектов – эмпирические исследования фиксируют это явление. То есть, вам могут сгенерировать вполне рабочий по синтаксису код, который делает не то, что нужно, или содержит скрытую уязвимость. Пример: модель красиво реализовала требуемый API, но перепутала поля и ввела неуловимый баг, или вставила устаревший метод из старой версии библиотеки (она же зачастую не чувствует актуальности знаний)
- Ограниченный контекст и знание домена. Без специальных приемов (Retrieval-Augmented Generation и проч.) модель не знает особенностей вашего проекта. Она опирается на общую тренировочную выборку. Поэтому ИИ пока плох в учёте специфичных требований, архитектурных ограничений конкретной компании. Он часто предлагает решения "в общем", которые могут не подходить к твоему legacy-коду или корпоративным стандартам. Приходится тюнить промпты, снабжать контекстом, либо смириться, что человеческая экспертиза нужна для узкоспециализированных мест
- Юридические и этические аспекты. В некоторых компаниях (особенно крупный enterprise, госы) нельзя просто взять и использовать внешний SaaS ИИ. Данные кода могут быть конфиденциальны, есть опасения утечки. Плюс, хранение исходников у стороннего вендора несет риски (вплоть до того, что сгенерированный код может нарушать чьи-то копирайты, а отвечать будете вы). По этим причинам где-то внедрение ИИ идет медленнее: нужно проработать политику, юридические соглашения, или разворачивать модели
on-prem - Противоречивые примеры и шум. В публичном пространстве много историй об успешном применении ИИ, но не всегда понятно, что стоит за цифрами. Если кто-то заявил "мы ускорили разработку на 50% с AI" – хочется спросить: за счет чего конкретно? как измеряли? какой ценой для качества? Наоборот, есть истории провалов, но часто неясно, что именно не сработало – то ли команда сопротивлялась новшествам, то ли выбрали не ту область. В общем, мы пока учимся на собственном опыте, и достоверных "рецептов" мало. Поэтому важно опираться на измеримые метрики (скорость, дефекты,
change failure rate, покрытие тестами,MTTRи тд) и тщательно отделять факты от мнений в каждом таком кейсе
Отдельно стоит отметить стратегии внедрения ИИ в разных условиях. Например, в небольшом стартапе без legacy-кода легче интегрировать новые инструменты: там можно хоть завтра дать всем разработчикам доступ к ChatGPT и смотреть на результат. А в крупной финтех-компании с регуляторными ограничениями ты так не сделаешь – придется продумывать контуры, где можно использовать облачные AI (например, только на несекретных данных), либо поднимать локальные модельки. Есть типовые подходы
- Чистый SaaS: использовать внешние
APIи сервисы (OpenAI,GitHub Copilot) на полную. Подходит компаниям, у которых нет особо секретного кода или персональных данных. Плюсы – быстро, не надо свою инфраструктуру. Минусы – риск утечек данных, зависимость от внешнего провайдера, вопросы комплаенса - On-prem (полностью локальное решение): развернуть модели в своей инфраструктуре, возможно, открытые LLM или лицензированные. Подходит крупным корпорациям, где важны безопасность и контроль. Плюсы – данные никуда не уходят, можно тонко настраивать. Минусы – дорого поддерживать, отставание в качестве моделей (как правило, внутренние уступают по качеству передовым облачным, если только вы не супергигант)
- Гибридные решения: что-то делаем через внешние API, но только на несекретных данных; для чувствительного – локальные stub-модели. Или запускаем пилоты в отдельных отделах, не трогая весь код компании сразу. Вводим политику использования ИИ: что можно грузить модели, что нельзя; как логируются запросы; кто имеет доступ и тд. Такой взвешенный подход позволяет начать получать выгоды, минимизируя риски
В России (РФ-контекст) к перечисленному добавляются свои нюансы: ограничения на использование западных облачных сервисов, акцент на импортозамещение (свои модели, вроде SberGPT и других). Типовая стратегия для энтерпрайза РФ сейчас – начать с внутренних пилотов на безопасных сценариях (генерация тестов, документации, миграций, помощь в triage инцидентов), параллельно выстроить политику (что можно отдавать модели, что нельзя) и отслеживать результаты. Постепенно масштабировать успешные кейсы. Многие крупные компании создали внутренние центры компетенций по AI, чтобы аккуратно, но планомерно идти к AI-assisted разработке
Сейчас ИИ реально сдвигает индустрию, потому что сочетание качества моделей, доступности инструментов и конкурентного давления достигло критической массы. Мы уже видим ускорение типовых задач (генерация тестов, код по шаблону, фиксы простых багов, некоторые модели уже завезли генерацию целых приложений), но вместе с тем обострились вопросы контроля качества, безопасности и организации процесса разработки. Далее мы посмотрим, куда это может привести в будущем, а главное – как перестроиться, чтобы извлечь максимум пользы и не потерять качество
Взгляд в будущее. Гипотезы и сценарии развития

Я не предсказатель, но гипотезы строить обязан, чтобы понять какие изменения в разработке ПО могут стать новой нормой через 3–5 лет благодаря ИИ. Самое сложное в данной задаче это отделить хайп от реальности. Обычно ошибки прогнозов такие
- сводят всё к одной крайности: «ВСЁ заменят ИИ» или «НИЧЕГО не изменится». Истина, скорее всего, посередине и сильно зависит от контекста
- неявно предполагают универсальность: мол, если где-то получилось внедрить AI-режим разработки, значит, у всех получится так же. На деле факторы успеха могут быть уникальны (тип проекта, культура команды, поддержка руководства и тд)
Ниже – некоторые гипотезы о будущем разработке, которые сейчас активно обсуждаются в профессиональном сообществе и литературе. Я маркирую их условно [A]/[B]/[C] где [A] означает высокую уверенность (почти неизбежно при соблюдении условий), [B] – средняя (реалистично через пилоты, хотя могут быть препятствия), [C] – более смелые или узкоспециальные предположения (требуют прорывов или особых условий). К каждой гипотезе важно понимать условия истинности – что должно быть верно, чтобы она реализовалась
[A]. Разработчик становится "наставником ИИ", а не автором каждой строчки. Идея: доля сгенерированного кода, тестов, конфигов и тд будет постоянно расти. Человек все больше выступает в роли постановщика задач и проверяющего, но не пишет все руками. Условия- качество генеративных моделей продолжит расти
- у команд будут инструменты верификации всего, что сгенерировано (полный автотест, статанализ и пр), иначе риск превысит пользу
- разработчики будут обучены правильному промптингу и работе с агентами. Контраргументы: могут появиться новые области, где генерация бесполезна (например, слишком творческие или узкие задачи), и там по-прежнему основная ценность – ручной кодинг
[A]. Основным "активом" команды станет не код, а конвейер производства изменений. То есть конкурентное преимущество – в том, насколько быстро и качественно вы умеете от идеи переходить к релизу при помощи автоматизированных процессов. Код можно скопировать, нанять подрядчика – это несложно. А вот выстроить дисциплину, которой подчиняются и люди, и машины (модели) – гораздо труднее. Условия- наличие в компании
DevOps-культуры, метрик качества, хорошей платформы - готовность вкладываться не только в фичи, но и в инфраструктуру разработки. Почему это гипотеза: потому что звучит абстрактно – многие бизнесы не верят, что вкладываться в "конвейер" важнее фичей. Тем не менее, все больше косвенных данных говорит: у тех, кто настроил крутой engineering system (автотесты, CI, мониторинг), внедрение ИИ дает кратный эффект ускорения, у остальных – хаос
- наличие в компании
[B]. Спецификации и критерии качества станут важнее кода. В парадигмеSE 3.0намерение (описание, что нужно сделать) и acceptance criteria (как проверить, что сделано правильно) – главные артефакты. Код – их следствие. Значит, роли аналитиков, архитекторов, тестировщиков, пишущих сценарии, возрастут. Условия- инструменты, позволяющие легко писать и поддерживать спецификации (возможно, тоже с помощью ИИ)
- культура, поощряющая тратить время на "подумать и описать" до кодирования. Риск: в маленьких стартапах это может быть "слишком тяжеловесно", они будут отказываться до последнего и ехать на vibe-coding + костылях. Но в больших системах иначе нельзя: без хороших спецификаций и автопроверок агенты нагенерят кучу ошибок
[B]. Разработчики поляризуются на "системных" vs "интуитивных". Уже сейчас ценность "инженеров системы" (которые понимают архитектуру, процессы производства и бизнеса, могут связать инструменты) растет, а спрос на просто "кодеров" снижается. ИИ делает ручной кодинг дешевле, но системное мышление дороже. Условия- действительно, генерация покрывает большинство шаблонных задач
- рынок труда начнет выделять таких инженеров (рост зарплат у тех, кто умеет автоматизировать, против тех, кто только фичи пилит). Признаки: это начинает происходить – в вакансиях все чаще ищут умение работать с ML-ассистентами, строить пайплайны, думать про метрики. Но вряд ли исчезнет потребность и в "сильных одиночках" – просто они будут эффективнее если вооружатся ИИ
[A]. "Узкие места" сместятся - большая часть генерации будет там, где есть автоматическая проверка, а в "опасных зонах" останется человек. Формируется своеобразнаязеленая зонаикрасная зонадля ИИ. Зеленая – это повторяемые задачи с четкими проверками: генерировать юнит-тесты, типовые CRUD-контроллеры, миграции БД, boilerplate-код, документацию из шаблона. Там можно позволить модели делать большую часть работы.Красная зона– места с высокой ценой ошибки или уникальной логикой: сложные архитектурные решения в том числе эволюционные, безопасность, оптимизация производительности, нетривиальные product-решения. ТамИИмаксимум помощник, а финальное слово за человеком. Условие- наличие границ и правил, где
ИИприменять безопасно, а где – нет, и донесение этого до команд. (См. также далее "Матрица по стримам", где в каждой роли выделены ускоряемые и человеческие части)
- наличие границ и правил, где
- Уровень автономности разработки вырастет, но не мгновенно до полного. Часто спрашивают: "А когда код будет писать себя сам, вообще без участия человека?" В терминологии автономности (как в беспилотных авто уровень 1–5) сейчас в среднем мы на уровне 2:
AI-assisted–ИИочень помогает, но человек главный исполнитель. Ближайшие реальные цели – уровни 3–4:AIвыполняет -> человек валидирует. Этоsupervised automationиpartial automation. Многие команды к этому придут в ближайшие 2–3 года. А вот полная автономия (уровень 5) – когда система сама генерит, сама проверяет и сама выкатывает без человека – это совсем иной уровень требований (формальная доказуемость, аудит, допуск к production-средам и пр). Это, возможно, станет реальностью лет через 5–10 в отдельных нишах (суперкритичные системы с формальной верификацией), но точно не массово завтра. То есть, ожидать, что появится кнопка «Сгенерировать мне весь HeadHunter заново» и она сделает идеально, – утопия на обозримый срок
Эти гипотезы – не предсказания Ванги, а рабочие сценарии. Внедряя ИИ-практики, полезно проверять условия: например, ты веришь, что спецификации – это ключ? Тогда спроси себя, выполнены ли у тебя в команде предпосылки (есть время на прописывание требований, есть экспертиза, нет ли сопротивления). Если нет – нужно сначала эту среду подготовить. Иначе гипотеза "не взлетит" именно у тебя
В целом, будь готов к тому, что скорость станет легко-достижимой целью, а вот качество и управляемость изменений – главным полем борьбы. Ключевой прогноз, даже, утверждение: «Скорость стала дешёвой. Качество стало стратегией». Победят те команды, которые научатся генерировать много, но при этом держать качество под контролем. А для этого понадобится новая модель разработки – как раз о ней далее
Парадигма SE 3.0: конвейер намерений, генераций и проверок
Мы подошли к центральной концепции – Software Engineering 3.0 (SE 3.0). Если SE 2.0 в 2010-х научил индустрию поставлять изменения конвейерно (CI/CD и сопутствующие практики), то SE 3.0 – следующий шаг: конвейер становится не только "транспортом для кода", но и частично «производством». В производство встроен ИИ
Раньше главным результатом работы команды был код (артефакт, создаваемый вручную). Теперь главным артефактом становится намерение + критерии правильности, а код – один из производных артефактов, получаемых автоматически. Формула SE 3.0
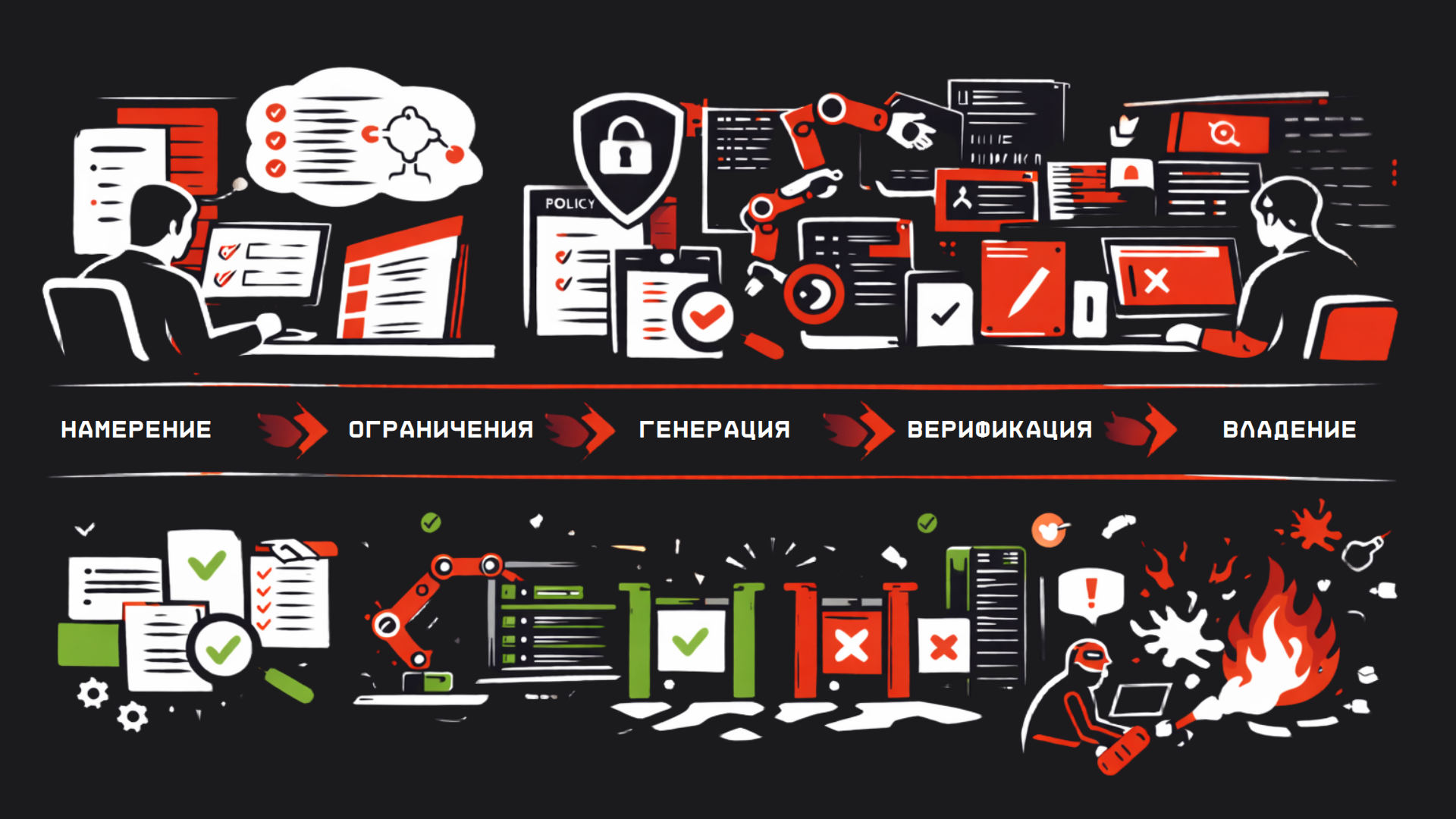
SE 3.0 = Ownership( Verification( Generation( Intent + Constraints ) ) )
Где
Intent- это намерение, спецификацияConstraints- это ограничения, политикаGeneration- это LLM/агентыVerification- это гейтыOwnership- это ответственность человека
Или можно было бы вместо композиции формулу изобразить с операторами перехода ->
SE 3.0 = Intent + Constraints -> Generation -> Verification -> Ownership
Стрелка тут означает оператор перехода/трансформации где я "беру операнд (Intent+Constraints и тд) и прогоняю через сл стадию, например генерации"
SE 3.0 – это "мы генерим ровно настолько, насколько умеем автоматически проверять и контролировать". Если попытаться ускориться без должных средств контроля, то ускорение обернется перепроизводством мусора: срыв сроков из-за переделок, инциденты на продакшене, регрессии, выгорание команды, расстройство бизнеса. Поэтому внедрение ИИ без соответствующего развития практик качества контрпродуктивно
Где сейчас индустрия на этом пути? Как отмечалось, примерно между 2-ым и 3-им уровнями автономности. Многие уже используют ассистентов для генерации кода и тестов, но финальная валидация и смысл остаются за человеком. Прорыв ближайших лет – научиться повышать долю задач, выполняемых AI правильно, оставляя человеку лишь подтверждающую роль (или разработку самых сложных частей)
Чтобы яснее представить SE 3.0, давай посмотрим на типичный поток процесса разработки в этой парадигме
Это пайплайн разработки в парадигме SE 3.0: от формулировки намерения до эксплуатационной обратной связи
В начале находится намерение – задача, сформулированная человеком. Это включает описание фичи или изменения, модель домена, явные acceptance criteria (что считаем успехом). Рядом – ограничения: политики, архитектурные правила, соглашения по стилю, требования безопасности. Эти два блока – вклад человека до начала кодинга. Далее вступают инструменты
- генерация. На этом этапе AI-модель или агент берет намерение (с учетом ограничений) и генерирует код, тесты, конфигурации, документацию – все артефакты, нужные для реализации задачи. Генерация может быть интерактивной (человек подправляет запросы) или полностью автономной в случае агентов. Результат – черновые изменения системы
- верификация. После генерации обязательны автоматические проверки: прогоны тестов (unit, integration, e2e), статический анализ кода, ревью по смыслу (например, агент или человек просматривает дифф на предмет логических ошибок), performance-тесты и тп. Здесь выявляются ошибки. Если какие-то проверки не пройдены – цикл возвращается: либо агенту дается обратная связь на доработку, либо человек правит и снова запускает
- security/compliance gates. Дополнительный слой гейтов: проверка безопасности зависимостей (скан уязвимостей), секретов в коде,
SBOM, требования к лицензиям, подпись артефактов, одобрения ответственных, соответствие регуляторным нормам. Эти проверки особенно актуальны для продакшен-систем: например, даже если код функционально верен, его нельзя вливать, если он тянет опасную библиотеку или не соответствует стандарту шифрования. Гейты могут быть полуавтоматические (требуют ручного аппрува при срабатывании) или автоматические блокирующие - интеграция и поставка. Если все предыдущие проверки позади и статус OK, изменение сливается в основную ветку, запускается
CI/CD. Происходит сборка, деплой на необходимый стенд или сразу в прод (в зависимости от политики релизов). Плюс, если нужны миграции баз данных или обновление инфраструктуры, это делается на этом шаге - эксплуатация. Внедренное изменение попадает в бой, где есть система наблюдаемости: метрики (например, скорость работы, потребление памяти), алерты на ошибки, логирование, сбор обратной связи от пользователей. Этот слой крайне важен: он позволяет выявить проблемные изменения уже в продакшене. Например, если после релиза выросло количество ошибок 500 на бэкенде, или метрика времени отклика ухудшилась – алерты сообщат команде, и она сможет откатить или исправить. Обратная связь от эксплуатации (постмортемы инцидентов, отзывы пользователей, новые идеи) поступает команде, замыкая цикл: эти данные формируют новые намерения для будущих задач
В SE 3.0-конвейере человек и ИИ работают в связке. Человек
- формулирует намерение, описывает требования и ограничения
- утверждает важные решения и несет ответственность за конечный результат
- делает финальную проверку по смыслу: «соответствует ли изменение требованиям домена, решает ли задачу пользователя?» – то, что автоматике не до конца под силу
ИИ (модели, агенты) берут на себя
- черновую реализацию – рутину кодирования по спецификации
- значительную часть финальной реализации тоже (при хорошем контроле)
- часть проверки: например, автоматически пишут и выполняют тесты, подсказывают, где возможны ошибки, проводят анализ покрытия и тп
А Платформа / процесс
- накладывает ограничения (policy-as-code)
- обеспечивает измеримость (метрики качества и риска)
- защищает от "скорости без контроля" (quality gates)
Человек отвечает на вопрос "что и зачем", а ИИ помогает с "как" – но под присмотром
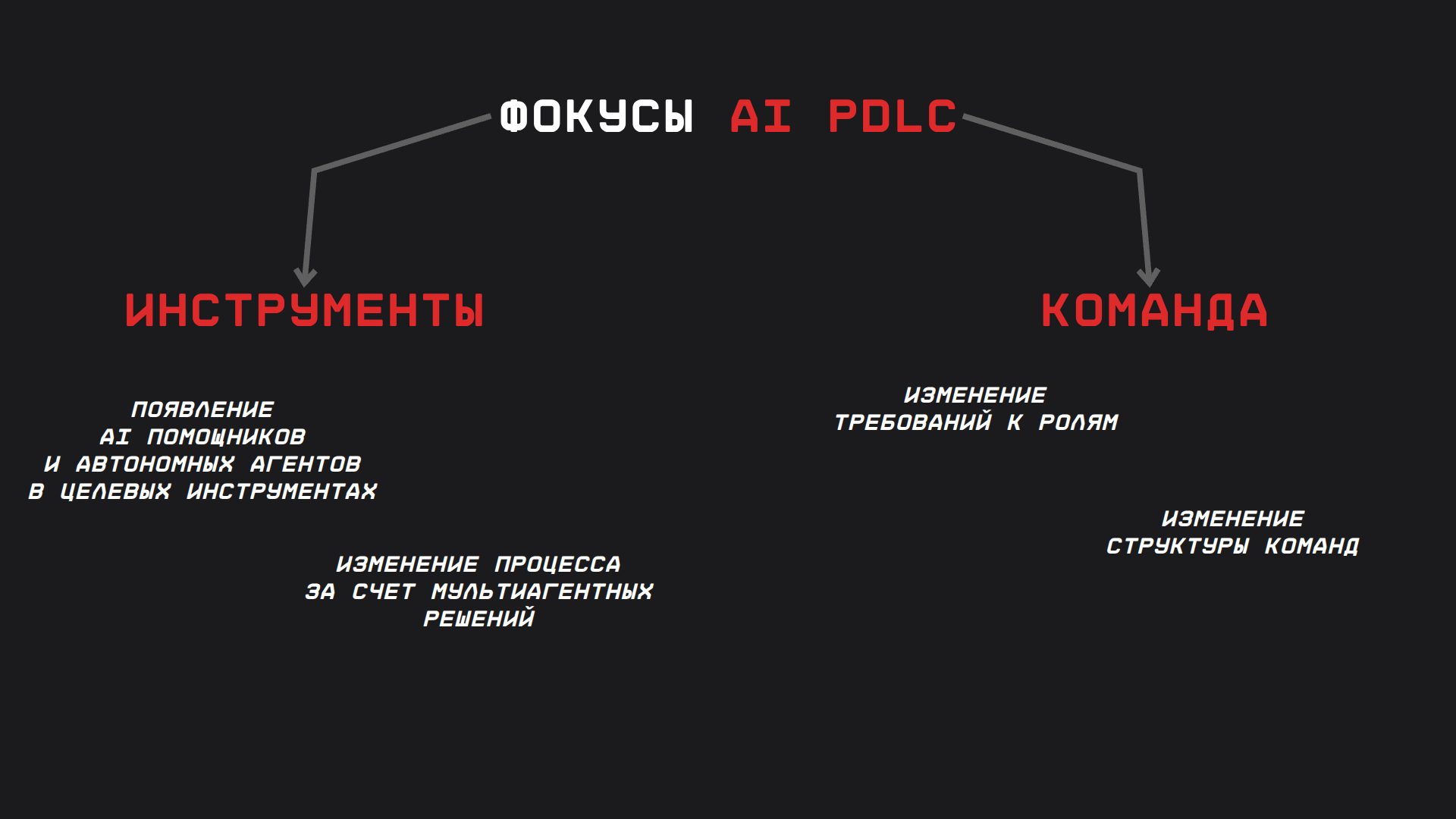
На практике переход к SE 3.0 – это трансформация на нескольких уровнях
- инструменты. В рабочий инструментарий разработки внедряются AI-помощники и агенты. Они перестают быть отдельными "чатами" в стороннем окне, а встраиваются прямо в
IDE, в системыCI/CD, в средства тестирования и мониторинга. Ваш редактор кода сам может подсказать готовый фрагмент,CIна этапеcode reviewпрогнать агент, который найдет возможные ошибки или обновит документацию, в системе алертов агент предложит гипотезу причины инцидента. То есть инструменты становятся интеллектуальными участниками процесса, а не пассивными исполняторами - Процесс. За счет автоматизации ускоряется производство артефактов. То, что раньше было медленным (написание кода, написание тестов), становится быстрым. Узким местом теперь становится не кодинг, а верификация и риск менеджмент: убедиться, что всё сгенерированное работает и не ломает систему. Поэтому процессы добавляют этапы и практики для эффективной проверки: более частые интеграции, обязательные гейты качества, дополнительные среды тестирования, новые подходы к
code review(например, focus review: ревьюер смотрит только ключевые моменты, а остальное доверяет автопроверкам) - команда и роли. Требования к навыкам меняются. Растет ценность архитектурного мышления, понимания инвариантов (неизменных правил корректности системы), умения формулировать качественные спецификации. Набор инженерных ролей может пополниться новыми функциями: AI-промпт-инженер (настраивает и обучает модель на нужный формат), AI-Ops специалист (следит за метриками эффективности агентов, обучает на новых данных), платформенный инженер SE 3.0 (отвечает за инфраструктуру конвейера: гейты, сбор метрик, guardrails). Уже сейчас ценность связки «сильный senior + ИИ» выше, чем просто сильный senior: потому что такой инженер способен сразу кратно усилить свою работу через ассистентов
Чтобы лучше понять, какие изменения по ролям происходят, рассмотрю далее дорожные карты роста для инженеров разных грейдов и специализаций. Но сначала закреплю пару важных принципов SE 3.0
- качество не проверяемое – качество недостижимое.
ИИускоряет производство артефактов, но качество появляется только там, где эти артефакты могут быть проверены автоматически. Это фундаментальное правило: «проверяемость» означает, что у нас есть способ однозначно сказать "это правильно / неправильно" без бесконечных субъективных споров. Значит, нужен механизм верификации для всего- для кода – юнит/интеграционные/e2e тесты, статический анализ, строгость типов, security-сканы, performance-тесты
- для API – контрактные тесты, схемы (OpenAPI/JSON Schema), контроль совместимости версий
- для требований – четкие acceptance criteria, примеры, тест-кейсы, зафиксированные инварианты домена (факты, которые всегда должны быть истинны)
- для инфраструктуры – policy-as-code, проверки конфигураций, механизмы обнаружения дрейфа (несоответствия фактического окружения коду инфраструктуры)
- для эксплуатации – SLO/SLI (цели и показатели надежности), алерты, пост-мортемы, регулярные chaos engineering тесты на отказоустойчивость
- для документации – doc-tests (примеры кода, которые сами проверяются), принцип "docs-as-code" (документирование через pull request с review), автоматическая генерация части доков из единого источника правды (например, OpenAPI генерит справочник API)
Почему это правило SE 3.0? Потому что теперь узким местом стало не написание (его ИИ удешевил), а проверка, что всё работает и безопасно. Раньше писать код дорого обходилось, теперь дешево – зато проверить, что код хороший – вот что дорого. Поэтому выигрывают процессы, где
- артефакты машиночитаемы (можно прогнать автоматические проверки)
- проверки автоматизированы (встроены в pipeline, а не полагаются на "вручную посмотрим потом")
- есть жесткие quality gates в CI/CD (никакой некачественный код не проходит дальше)
- есть метрики результата (например, классические DORA: Lead Time, Change Failure Rate, MTTR, Defect escape rate), т.е. ты отслеживаешь фактическое качество и скорость своего конвейера
ИИ усилит твою текущую систему, но не починит ее слабости. Если в организации бардак, метрики не верят, архитектура монолит Legacy – просто добавив агентов, ты не получишь чудо. Наоборот, AI лишь ускорит и усилит то, что уже есть – в том числе хаос и слабости. (это я разберу в разделе про анти-паттерны внедрения), поэтому переход к SE 3.0 – это не внедрить новый инструмент, а организационно-инженерная трансформация: она затрагивает культуру, процессы, структуру ответственности
Дорожные карты развития инженеров (от Intern до Lead)

Как же практически расти инженеру в эпоху AI-assisted разработки? Какие навыки станут критичны на каждом этапе карьеры? Представляю сводную таблицу: грейд -> фокус роли -> необходимые навыки -> типичные задачи с ИИ -> артефакты, которые обязан поставлять -> главные риски в работе. Эта "cheat sheet" может служить ориентиром, чему учиться и на что обращать внимание
ИИ меняет не названия профессий, а распределение ценности между навыками. Раньше можно было выделяться просто скоростью кодинга или глубоким знанием фреймворка. Теперь скорость черновой реализации обесценилась – выигрывают те, кто умеет четко ставить задачу, ограничивать решение рамками и проверять результат
Как пользоваться таблицей: найди свой текущий грейд (или тот, к которому стремишься). Отметь, какие ключевые навыки у тебя уже есть, а каких не хватает – их стоит подтянуть в первую очередь. Также посмотри на типовые артефакты и риски для твоего уровня: это подсказки, на что делать акцент в работе
Таблица: грейд -> фокус -> навыки -> артефакты -> риски
| Грейд | Главная цель / фокус развития | Must-have навыки | Типичные задачи с ИИ | Артефакты, которые обязан поставлять | Топ-риски |
|---|---|---|---|---|---|
| Intern (стажер) | Научиться выпускать маленькие изменения безопасно | основы Git, PR-воркфлоу; чтение чужого кода; базовое тестирование; умение задавать вопросы ИИ с критериями | объяснение кода; генерация шаблонных функций; простые unit-тесты | небольшие PR с понятным описанием; исправления по замечаниям ревью; базовые тесты к своему коду | бездумный копипаст без понимания; отсутствие тестов вовсе |
| Junior | Научиться делать фичу end-to-end под контролем (с помощью ментора) | декомпозиция задач; базовая архитектура (слои, модули); отладка ошибок; написание тестов; чтение логов | генерация простых компонентов/UI или API; автосоздание тестовой "обвязки" для кода; помощь ИИ в документировании PR | фича с описанными acceptance criteria; юнит-тесты и логирование основных сценариев; своевременные фиксы багов | «делает быстро, но ломает часто» – спешка без понимания качества; слишком большие заливки кода одним куском |
| Middle | Делать команду быстрее без потери качества (рутинные задачи – быстрее, сложные – надежно) | проектирование модулей; API-контракты; тест-стратегия (какие тесты нужны и где); смысловое ревью кода (проверка логики, не стиля); умение разбираться с продакшн-проблемами | миграции кода (с помощью агентов); рефакторинг legacy-модуля; генерация интеграционных тестов; настройка CI-пайплайна под новый тип проверки | архитектурные decision records (ADR); план тестирования фичи; качественные code reviews (найдены и описаны проблемы) | «diff-торнадо» – генерирует огромные изменения, которые сложно ревьюить; скрытый техдолг (быстрые решения без расчета последствий) |
| Senior | Управлять сложностью и рисками (делать так, чтобы система устояла при ускорении) | архитектурное видение; знание и внедрение SLO/наблюдаемости; обеспечение безопасности (секреты, доступы, supply chain); умение находить компромиссы в дизайне; наставничество инженеров | дизайн сложного решения с ограничениями; автоматизация quality gates; реализация сложного рефакторинга через агента; внедрение новых практик (например, static code analysis и многие другие правила производства) | архитектурные решения, обеспечивающие безопасность генерации (границы модулей, "guardrails" для агентов); новые стандарты или политики для команды; улучшенные метрики качества (низкий defect escape, высокое покрытие и пр.) | ускорение без контроля – команда генерит кучу фич, но системы контроля качества не усилены -> рост инцидентов ("риск-инженерия"); техдолг, который не виден сразу; выгорание, если пытается вручную проверять всё за всеми |
| Lead (тимлид, руководитель разработки) | Сделать производство изменений устойчивым и предсказуемым на уровне команды/продукта | организационное мышление (как распределить зоны ответственности, командные процессы); метрики SDLC и качества (Lead Time, CFR, MTTR, дефекты); управление культурой качества; знание платформенных возможностей компании. И еще одно, что мне лично хочется видеть - развитие инженерной культуры | разработка и внедрение политики ИИ в команде; обучение всех членов работе с новыми инструментами; выбор пилотных проектов для AI-внедрений; анализ метрик "до и после" внедрения; улучшение процесса релизов/онбординга с ИИ | формализованный Definition of Done команды; внутренние стандарты (код-стайл, шаблоны, соглашения); "золотая дорожка" для типового сервиса (шаблон проекта + CI + мониторинг); рост метрик эффективности без ухудшения качества (улучшенные DORA показатели) | бюрократия (переусердствовал с регламентацией – команда задыхается, потеря гибкости); «меряем не то» (фокус на метриках ради метрик, а не ради реальных улучшений); размытый ownership – команда не знает, кто за что отвечает, все полагаются на "агента/систему" и не чувствуют ответственности |
Таблица не покрывает абсолютно всё, но показывает суть изменений: с ростом грейда всё меньше ценится умение быстро писать код и всё больше – умение выстроить безопасный процесс, обеспечить проверку и зрелость разработки. Даже intern теперь ценен не количеством кода, а дисциплиной: лучше меньше, да лучше, с тестами и понятными описаниями. А lead, помимо технических знаний, должен думать об организации и метриках
Развитие, конечно, не останавливается на текущем грейде. Для каждого уровня есть свои мини-челленджи на 30/90/365 дней – мы их приведем в конце статьи (в разделе с чек-листами), чтобы желающие могли конкретно спланировать свой рост.
Дорожные карты по направлениям (Frontend, Backend, DevOps, QA, Design, System Analysis)
Я рассмотрел рост по грейдам, то есть по уровню ответственности. Теперь опишу, как именно внедрение ИИ меняет работу в разных инженерных стримах (специализациях) - везде одинаково. Нет. Ускорение от AI наиболее заметно в одних типах задач и меньше в других. Ниже сводная матрица по основным направлениям
- что ИИ ускоряет – какие части работы в этом стриме лучше всего автоматизируются, где модели дают максимальный буст
- что остается "человеческим" – зоны, где по-прежнему нужен живой опыт и решения, ИИ там мало поможет или может навредить
- новые/усиленные артефакты – какие новые документы, метрики или процессы появляются, чтобы интегрировать ИИ безопасно
- метрики успеха – как измерять результативность ИИ-внедрения в данном стриме (чтобы понять, стало ли лучше)
- топ-риски – основные опасности или подводные камни при ускорении этого направления с помощью
AI
Матрица по стримам: стрим -> ускорение -> человеческое -> артефакты -> метрики -> риски
| Стрим | Что ИИ ускорит | Что останется "человеческим" | Новые/усиленные артефакты | Метрики успеха | Топ-риски |
|---|---|---|---|---|---|
| Front-end | Генерацию UI-компонентов, верстки; автосоздание тестов (юнит, скриншотных); миграции дизайн-системы (замена старых компонентов на новые). Boilerplate для приложения | UX-решения и компромиссы; оптимизация производительности; единый дизайн-визуальный стиль (бренд, ощущение продукта) | UI-контракты (документ, описывающий API компонентов); чек-листы доступности (a11y); визуальные тесты скриншотов | Веб-метрики: LCP/INP (производительность), число багов UI после релизов, velocity (скорость выдачи фич) без роста регрессий | Проблемы доступности (a11y) – модель может не соблюдать; деградация производительности незаметно; «визуально ок – логически нет» (интерфейс выглядит правильно, но бизнес-логика нарушена) |
| Back-end | Генерацию типовых эндпоинтов, CRUD-логики; шаблонные миграции БД; автогенерацию тестов для API; написание boilerplate-кода (DTO, мапперы). Boilerplate для приложения | Проектирование доменной модели; обеспечение целостности данных; критичные алгоритмы и оптимизации; вопросы безопасности и прав доступа | Схемы данных (ERD, OpenAPI спецификации); контракты между сервисами; SLO (цели надежности) и ADR (решения с обоснованиями); автоматизированные проверки инвариантов (доменных правил) | Change Failure Rate, MTTR; количество инцидентов; отсутствие деградации БД (регрессий в миграциях) | Неверные инварианты: агент может не учесть тонкое правило бизнеса и нарушить его; миграции без возможности отката; ошибки в логике, которые проходят компиляцию, но приводят к сбоям при нагрузке |
| DevOps/SRE | Автоматизация IaC (Infrastructure as Code) – генерация конфигов; помощь в triage инцидентов (предложить причину по логам); генерация runbooks (инструкций по реагированию); автосоздание alert-правил под новые сервисы | Определение политики доступа и безопасности; архитектурные решения надежности (как распределить нагрузки, резервирование); управление рисками инфраструктуры (что где разворачивать, чтобы было безопасно) | Policy-as-code (правила в коде, контролирующие инфраструктуру); актуальные runbooks, генерируемые с помощью ИИ и обновляемые; SLO/SLI для новых сервисов (цели и индикаторы надежности) | MTTR (mean time to recovery); общий uptime/availability; частота инцидентов по вине конфигурации | «Автоматизация без границ» – агент может внести изменения в инфраструктуру, которые нарушат политику, если нет ограничений; утечки секретов через неосторожные промпты; |
| QA / Testing | Генерацию тестовых случаев (в том числе на основе описания требований); создание тестовых данных; чек-листы для ручного тестирования; автоматизация частей регрессионного тестирования | Разработка стратегии тестирования (какие случаи критичны, приоритеты); проработка сценариев крайних случаев; определение критериев приемки (что считать "пройденно"); исследовательское тестирование (exploratory) там, где нужна интуиция | Документированные test strategy (как покрывается функциональность тестами); подход risk-based testing (фокус на рисковых местах); отчетность по качеству (метрики дефектов) | Defect escape rate (процент багов, прорвавшихся в прод); flaky test rate (процент нестабильных тестов); покрытие критических сценариев тестами | Иллюзия покрытия: модель генерит много тестов, но они тривиальные и не ловят реальные баги; flaky-тесты: автогенерация может создать нестабильные тесты, бьющие по CI; потеря "человеческого взгляда" – когда полагаются на автотесты и упускают неожиданные проблемы |
| Design / UX | Быстрая генерация вариантов UI (экраны, иконки) по текстовому описанию; автоподбор цветовых схем, стилей; генерация текстового контента (лейблы, описания) на основе заданного тона | Осмысленность UX: соответствие дизайна потребностям пользователя; пользовательские исследования, интервью; консистентность опыта; креативные идеи, выходящие за шаблоны | Design tokens (единые цвета/шрифты, в коде); style guidelines (гайдлайны по UX, возможно, сгенерированные на основе лучших практик); сценарии UX (user journey описания, которые тоже можно генерировать и проверять) | Пользовательские метрики: conversion rate, retention, удовлетворенность; скорость выполнения дизайнерских итераций | «Красиво, но не решает проблему»: ИИ может нарисовать эффектный интерфейс, который не подходит аудитории или усложняет пользовательский путь; риск потери уникальности продукта (если дизайн генерируют по общим шаблонам, теряется идентичность); недосказанность в UX-решениях (модель не поймет всех нюансов поведения пользователей) |
| System Analysis / Requirements | Генерация черновиков спецификаций, user story по общему описанию; автоматическое составление acceptance criteria; анализ пользовательских отзывов и логов для выявления требований; консолидация документации (сбор требований в единый документ) | Общение со стейкхолдерами: выяснение истинных потребностей; приоритизация фичей; определение границ системы (что делаем, а что нет); управление ожиданиями бизнеса | Единый глоссарий домена, поддерживаемый (в том числе автоматически) в актуальном состоянии; трассируемость требований (traceability matrix, где ИИ помогает линковать требования с тестами и кодом); улучшенные шаблоны спецификаций (AI может проверить их на полноту) | Rework rate (сколько процентов фич потом переделывается из-за неверных требований); scope creep (рост объема требований вне плана); удовлетворенность заказчика пониманием его задачи | Размытые требования: модель может написать красивый текст требований, который ничего не значит конкретно (вода); потеря контекста – если аналитик полагается на ИИ в интервью, могут упустить важные нюансы; зависимость от шаблонов – требования пишутся "как у всех", не учитывая уникальность бизнеса. |
Из этой матрицы видно, что в каждой сфере свои "зеленые" зоны для ИИ и свои "красные" зоны, требующие опыта. Например во Frontend – генерация компонента ок, а вот проверить, что он доступен для людей с ограничениями (a11y) и вписан в UX-продукта, должен человек (или авто-тесты, настроенные человеком). В Backend – сгенерировать API-шаблон легко, но понять, как он впишется в общую модель данных и не нарушит ли инварианты – задача архитектора. И так далее
Общее правило SE 3.0 для всех стримов ИИ ускоряет производство артефактов, но ценность приносит только там, где эти артефакты проверяемы. Это значит: инструменты для автоматической проверки должны покрывать все места, куда ты пускаешь ИИ. Иначе исполненный риск перевесит пользу
Прежде чем, скажем, доверить агенту генерировать миграции базы данных, убедись, что у тебя есть хорошие интеграционные тесты и бэкапы на случай ошибок. Хочешь, чтобы агент правил код? – убедись, что он делает это в рамках pull request, который пройдет код-ревью и автотесты, а не прямо в прод. Хочешь, чтобы ИИ писал документацию? – стандартизируй ее формат, чтобы потом можно было проверить ссылки, примеры, синхронность с кодом
Именно сочетание «платформа + гейты + ИИ» превращает хаос в конвейер. Когда все повторяемое автоматизировано, а все рискованное подконтрольно, команда может даже сокращаться в размерах (появляется концепт "микрокоманд" – очень маленьких коллективов, эффективно ведущих продукт с помощью мощной платформы и AI). Но микрокоманды не возникают сами – они возможны только при очень хорошем инженерном окружении (quality gates, observability, golden paths), иначе быстро превратятся в группу пожарных, заваленных проблемами
Почему SE 3.0 может не взлететь. Организационные анти-паттерны
При всех перспективах, на пути к этой "светлой будущей" разработке есть серьезные организационные барьеры. Любая архитектура SE 3.0 (инструменты, гейты, AI-driven процессы) подразумевает базовое условие: организация хочет видеть правду о своей производительности и качестве. Иначе говоря, готова мерить параметры разработки и реагировать на них. К сожалению, на практике это условие часто не выполняется
Антипаттерны
Большинство провалов внедрения AI-инструментов связано не с плохими моделями и не с кривыми алгоритмами, а с тем, что организация системно отключает механизмы обратной связи – осознанно или нет. Если в компании не любят метрики, избегают ретроспектив, наказывают за правду – никакой ИИ не поможет, он только ускорит катастрофу. Давай рассмотрим типичные анти-паттерны, которые делают невозможным устойчивый переход к AI-driven разработке, даже если "агентов подключили"
- отключение системы от метрик.
SE 3.0требует измеримости – ты должен знать скорость, качество, стабильность. Но нередко метрики либо формальны («ну да, какие-то дашборды есть»), либо ими пренебрегают. Проявления: метрики существуют, но не влияют на решения; неудобные цифры "временно" скрывают; алерты ставят на mute или подтасовывают, чтобы "не мешали". В такой среде AI-ускорение просто разгоняет движение вслепую. Ошибки копятся быстрее, при этом у всех иллюзия прогресса ("мы же больше кода пишем!") – Контр-меры: зафиксировать набор ключевых метрик, по которым ни при каких обстоятельствах нельзя хитрить (например, CFR – процент неудачных релизов, MTTR – время восстановления, defect escape – баги на проде). Связать решения о релизах и экспериментах с показателями: т.е. "ускоряемся, если метрики позволяют". Сделать отключение метрик сложным и публичным: если кто-то хочет отключить мониторинг, это должно обсуждаться, а не по тихому - гашение «сигнальных систем». Ретроспективы, постмортемы, ревью процессов – все эти практики дают возможность организации учиться на ошибках. Анти-паттерн: считать их бюрократией, или превращать в поиск виноватых, или просто отменять как «неприоритет – нам кодить надо, не болтать». В итоге компания теряет чувствительность к собственной деградации. Если отменить ретро – команда не переварит уроки, если постмортем превращен в показательное наказание – люди будут скрывать проблемы. В среде, где отключены эти "нейроны обратной связи", AI-driven конвейер будет гнать изменения, но без механизма самокоррекции – Контр-меры: наоборот, усиливать культуру открытого обсуждения. Честные ретроспективы с действиями, постмортемы без поиска виноватых (фокус на системе, а не на личностях), регулярные ревью процессов
- создание bus factor’ов (узких мест знаний). В здоровых командах знания распределены, в дисфункциональных – концентрируются у отдельных "незаменимых" людей. Если все ключевые решения завязаны на одном архитекторе, документация устарела или отсутствует («только автор разбирается») –
ИИне спасет, а усугубит ситуацию. Он будет усиливать того же единственного "героя", потому что контекст и контроль у него. В итогеbus factorтолько возрастет – уйдет этот человек, и вместе с ним уйдет управление агентами – Контр-меры: ротация людей по проектам, менторство, хранение знаний не в головах, а в системе (документы, базы знаний). Также – не пускать ситуацию, когда "только старший эксперт может настроить нашего агента, остальные не понимают" - неротация руководства и застывшие структуры. Связано с предыдущим, но на уровне процессов: если годами одни и те же люди контролируют правила, гейты, интерпретацию метрик, велик риск «закостеневшего конвейера». Формально может быть суперсовременный процесс, а фактически – он не умеет меняться, т.к. никто не пересматривает подходы. Любые проблемы объявляются виной "недостаточно старательных команд", а не дефектом архитектуры управления. В такой ситуации любая инициатива (в том числе
AI-инициатива) либо загнется, либо превратится в декорацию: ведь систему улучшать не дают, "и так все хорошо, это люди кривые" – Контр-меры: сменяемость ролей, внешний аудит процессов, культура, допускающая признание ошибок в самой структуре. Новые идеи (вродеSE 3.0) должны впитываться, а не отторгаться иммунитетом - имитация внедрения (коррупция целей). Нередко
AI-трансформация становится витринным проектом: много красивых слов, доклады на конференциях, а по факту – ноль изменений. Например: выбор инструментов не по нуждам разработки, а по чьим-тоkickbackинтересам; пилот запустили, отчитались, но не масштабируют (галочку поставили – и ладно); вместо инженерных критериев успеха вводят политические (главное – "мы объявили обAI, инвесторы довольны"). В такой атмосфереИИиспользуется не как средство улучшить разработку, а как маркетинговый аргумент. Естественно, реальной ценности он не приносит – Контр-меры: ставить цели в терминах метрик (ускорили релиз на X, снизили баги на Y), а не просто "внедрить модный инструмент". Спрашивать с руководства за результаты, а не за презентации.Эффект Гудхартаздравствуйте - размывание ответственности скоростью. Очень опасный момент: ускорение процессов часто используется, чтобы размыть ownership. Когда случается проблема, говорят: "это не я, это агент сгенерировал, времени не было проверять". Или: "модель так предложила, я просто поверил". В культуре, где ответственность не закреплена,
AI-drivenпроцесс быстро деградирует в фабрику регрессий. Все гонятся за скоростью, никто не отвечает за последствия – Контр-меры: жестко оговаривать: использование ИИ не снимает ответственности. За каждый мердж в репозиторий отвечает конкретный инженер или тимлид, не важно, кто писал код – человек или модель. В вводных документах для команды прямо прописать: "Делаем быстрее – но отвечаем так же, как если бы делали сами". И при разборе инцидентов никогда не принимать оправдание "это ИИ виноват" – спрашивать, почему выпустили в прод непроверенное
Все эти анти-паттерны критичны потому, что ИИ усиливает существующие свойства системы. Он не лечит организационные болезни – он делает их более масштабными и быстрыми. Если компания не переваривает плохие новости, не доверяет данным, боится прозрачности, то AI-driven PDLC приведет не к чудесному росту, а к ускоренной деградации под видом прогресса. Будут генерироваться горы кода, метрики качества никто не увидит (или их "подправят"), и в один момент всё рухнет – внезапно для тех, кто смотрел только красивые отчеты
Переход к SE 3.0 – это, в первую очередь, испытание организационной зрелости. Это не столько про выбор AI-модели или покупку лицензии, сколько про готовность компании честно смотреть на свои процессы, измерять их и изменять. Успех трансформации на 80% зависит от культуры обратной связи, ответственности и открытости, и лишь на 20% – от конкретных технологий
Чтобы помочь выявить слабые места и проработать контрмеры, можно воспользоваться чек-листом анти-паттернов
Чек-лист анти-паттернов
1. Отключение системы от метрик
Анти-паттерн Метрики существуют формально или используются избирательно. Неудобные показатели игнорируются или "временно" отключаются
Наблюдаемые симптомы
- решения принимаются без ссылок на данные
- рост инцидентов объясняется "внешними факторами"
-
AI-ускорение не отражается в стабильности или качестве -
DORA/SPACEиспользуются только в отчётах
Контр-меры
- зафиксировать набор неизменяемых метрик (CFR, MTTR, defect escape etc)
- связать решения (релизы, масштабирование, автономность агентов) с показателями
- сделать отключение метрик видимым и обсуждаемым событием, а не технической правкой
2. Гашение сигнальных систем (ретро, постмортемы, ревью процессов)
Анти-паттерн Ритуалы обратной связи формальны или отменяются как "неприоритетные"
Наблюдаемые симптомы
- ретро без действий
- постмортемы без причин и системных выводов
- повторяющиеся инциденты одного класса
- рост цинизма в командах
Контр-меры
- отделить ретро и постмортемы от оценки персонала
- фиксировать системные причины, а не человеческие ошибки
- ввести правило: без RCA -> нельзя повышать автономность или скорость
3. Намеренное создание bus factor
Анти-паттерн Ключевые знания и решения концентрируются у отдельных людей
Наблюдаемые симптомы
- критичные изменения возможны только "через одного человека"
- документация устаревает или отсутствует
- агенты и инструменты "помогают" только одному носителю контекста
Контр-меры
- сделать знания и контекст артефактами (
ADR,runbooks,инварианты) - ограничить возможность быть единственной точкой принятия решений
- считать
bus factorинженерным риском, а не личной особенностью
4. Отсутствие ротации руководства и архитектурных ролей
Анти-паттерн Одни и те же люди годами контролируют правила, гейты и интерпретацию метрик
Наблюдаемые симптомы
- проблемы всегда "в командах", а не в архитектуре
-
platform/golden pathsне пересматриваются -
AI-инициативы застревают в пилотах
Контр-меры
- периодический пересмотр архитектурных и процессных решений
- ротация ответственности за гейты и платформу
- независимые ревью конвейера (внутренние или внешние)
5. Коррупция и имитация внедрения
Анти-паттерн
AI-инициативы используются как витрина или источник личных выгод
Наблюдаемые симптомы
- выбор инструментов без архитектурного обоснования
- "успешные пилоты" без масштабирования
-
KPIпо "активности", а не по результату
Контр-меры
- жёсткая привязка
AI-инициатив к измеримым эффектам - прозрачность критериев выбора инструментов
- публичное закрытие пилотов, которые не дают эффекта
6. Подмена ответственности скоростью
Анти-паттерн
Рост скорости используется для размывания ownership
Наблюдаемые симптомы
- "это сгенерировал агент" вместо объяснения решения
- отсутствие владельца риска
- частые откаты без анализа причин
Контр-меры
- обязательное указание владельца изменений
- запрет на деплой без ответственного лица
- правило: автономность растёт только вместе с ответственностью
7. Страх прозрачности
Анти-паттерн Организация избегает полной наблюдаемости и аудита
Наблюдаемые симптомы
- сопротивление логированию и трассировке
- закрытые отчёты по инцидентам
- недоверие к автоматическим системам контроля
Контр-меры
- сделать прозрачность нормой, а не инструментом наказания
- разделить аудит и санкции
- использовать наблюдаемость как средство обучения системы
что SE 3.0 это скоростной автомобиль и поедет он, только если у вас есть тормоза, ремни и опытный водитель. Тормоза – это метрики и гейты качества; ремни – процессы и политика ответственности; водитель – культура команды. Без этого супер-двигатель ИИ лишь разгонит машину в стену
План действий: что делать 30 / 90 / 365 дней (инженеру, лиду, компании)
Новые идеи хороши, но без плана превращения их в реальность они быстро забываются. Поэтому завершу практическими чек-листами: что конкретно можно сделать в ближайшие 30 дней, 90 дней и 365 дней, чтобы продвинуться к эффективной работе с ИИ в разработке. Ниже три списка – для индивидуального инженера, для техлида/тимлида, и для уровня компании в целом. Эти шаги составлены так, чтобы их реально было выполнить
Для инженера (личный план)
30 дней
- выбрать 2 сценария, где ИИ безопасно помогает лично вам: например, (а) написать или обновить тесты, (б) отрефакторить кусок кода, (в) сгенерировать документацию, (г) проанализировать логи/стектрейсы (triage). Попробовать применить ассистента в этих сценариях и оценить эффективность
- внедрить для себя правило: «любой PR — с намерением, критериями и проверкой». То есть каждое изменение снабжать описанием, зачем оно, что должно работать, и проверять перед отправкой (прогонять тесты, линтеры)
- сделать шаблон запроса к ИИ (prompt), который ты будешь использовать по максимуму: структура вида контекст -> цель -> ограничения -> критерии правильности -> желаемый формат ответа. Использовать его при обращении к моделям, вместо беспорядочного "стрима мыслей"
- потренироваться объяснять diff после генерации: всякий раз, когда агент выдал код, представь, что ты на ревью – поясни (самому себе или товарищу), что изменилось и почему это правильно. Ты должен понимать каждый фрагмент, который принимаешь
- добавляй минимум 1 проверку качества в каждый свой PR. Например, если раньше не писал тесты – начни хотя бы с одного элементарного теста на новую функцию. Или подключи новый линтер/стат.анализатор локально и фикси предупреждения
90 дней
- собери свой базовый "набор гейтов" локально: убедись, что на твоей машине (или CI для твоего pet-проекта) всегда запускаются тесты, линтер, типизация (если язык), базовый статанализ. Сведи это в один скрипт, который вы гоняешь перед каждым пушем
- освой стратегию "малые итерации" с ИИ: научись разбивать большую задачу на цепочку маленьких поколений. Не проси у модели сразу гигантский класс на 100500 строк, а двигайся поэтапно: сначала сгенерируй интерфейс, потом отдельные методы и тд. Это снизит "дифф-нагрузку" и улучшит понимание
- реализуй 1 небольшую функцию/проект, где ИИ существенно помог, но качество ты обеспечил тестами и мониторингом. То есть продемонстрируй, что можешь вписать AI-ассистента в цикл разработки без ущерба для надежности
- научись работать с инвариантами своего проекта: сформулируй несколько ключевых правил, которые всегда должны соблюдаться ("X никогда не null", "сумма дебетовых транзакций = сумма кредитовых" и т.п.), и добавь проверки или тесты на них. ИИ может ускорить код, но ты должен знать, какие законы он не имеет права нарушать
365 дней:
- стань человеком, который ускоряет команду безопасно. Это более общее – проверь, что за год ты хотя бы в одном месте внедрил какой-то gate или стандарт. Например, настроил CI-пайплайн на запуск новых проверок, написал internal-линтер правило, обучил коллег чему-то. Прояви себя как проводник практик
SE 3.0. - прокачай системное мышление: углубись в архитектуру, изучи принципы проектирования, инфраструктуру, безопасность – особенно в части своего стрима. Например, ты фронтендер – разберись, как устроены бэкенд-API твоего продукта или как настроены CI-скрипты, выйди за пределы чисто своего кода. Ценность инженера теперь в широте контекста (сейчас время когда
M-spapingреально становится возможным. Только учти когнитивный контекст - в энтэрпрайз этот зверь может обитать не повсеместно. Причина - корпоративный налог) - научись проводить "миграции без пожаров": выбери что-то устаревшее (библиотеку, модуль) и попытайся перевести на новое с помощью ИИ, но по всем правилам: сделай план миграции, напиши тесты на ключевые сценарии, предусмотри откат, мониторь на каждом шаге. Если сможешь так провести изменение – это высший пилотаж инженерной зрелости
Для лида / техлида (план для руководителя команды)
30 дней:
- зафиксируй политику использования ИИ в команде: определи зоны – что считается зеленой зоной (можно смело использовать AI-инструменты на таких-то данных и задачах), желтой (с осторожностью, нужны ревью), красной (строго запрещено, например отправлять в публичный
ИИклиентские персональные данные или секретный код). Прописать также, какие логи вести: например, требовать, чтобы всеAI-запросы шли через корпоративный прокси и сохранялись (для аудита) - введи базовый Definition of Done для задач с учетом
AI: например, "сделано" означает, что код написан, автотесты пройдены, если генерился черезAI– добавлены комментарии, зачем так, проверены все FIXME. Согласовать с командой и сделать обязательным - выбери 2–3 сценария пилота с низким риском, чтобы попробовать
AIв действии на проекте: например, нагенеритьunit-тесты для старого модуля; или написать документацию к API с помощьюChatGPT; или использовать Copilot для миграции с одной библиотеки на другую. То есть где потенциальная ошибка не критична, зато можно быстро оценить эффективность - выбери, какими метриками "до/после" будешь мерить успех пилота: например, время
code reviewдо и после внедренияAI-ассистента; количество багов, найденных на тестировании; скорость выполнения определенного типа задач. Заранее собрать "до", чтобы потом сравнить
90 дней
- проведи пилот(ы) на 1–2 командах, зафиксируй результаты метрик и собери качественный фидбэк (опроси участников: что понравилось, где были проблемы). На основе этого реши, масштабировать ли практику
- введи шаблон PR и правило лимита размера PR: договорись с командой о формате Pull Request (описание намерения, чек-лист, ссылки на требования) – возможно, сгенерируй markdown-шаблон для них. И установи культуру: "PR > 500 строк кода не одобряем, надо бить на части". Это значительно упростит и human-ревью, и работу агентов
- настрой quality gates в CI как "необсуждаемый минимум": например, порог coverage, или запрет мерджить, если падает линтер/стат. анализ. Сделай так, чтобы эти проверки были автоматическими стоперами, а не на совести разработчиков. Это дисциплинирует и людей, и не даст
ИИпроскакивать с нарушениями - создай библиотеку внутренних промптов/шаблонов задач: по сути, задокументируй лучшие запросы к
ИИ, которые используешь в команде, чтобы другие могли их применять. Стандартизируй стиль: например, решили, что мы всегда просим "explain like I’m 5" в конце для пояснений кода – запиши это. Такая база позволит быстро обучать новичков эффективному использованиюAI-инструментов на твоём проекте
365 дней
- построй внутреннюю "золотую дорожку" (golden path) для типовых сервисов/задач с
AI: то есть создай шаблонный проект или набор скриптов, где сразу включены необходимые гейты, настроены подключенияAI(допустим, обертка над API модели, которая можно дергать в тестах или CI). Чтобы каждый новый сервис в компании уже рождался с поддержкой этих практик - внедри policy-as-code и аудит действий: если у вас появляются автономные агенты, обязательно нужны ограничения на их действия (пусть работает только в таком-то репо, только с такими правами, лимит изменений X) и логирование всего, что он делает (чтобы потом можно было выяснить, кто именно залил баг – человек или бот, и почему). За год можно это спланировать и реализовать
- подними зрелость эксплуатации: за год постарайся внедрить
SLO/SLIдля основных сервисов, наладь процесс постмортемов, автоматизировуй сбор метрик. Иными словами, параллельно сAI-инициативами, подтяниops-культуру, без которой все это хрупко - сделай обучение и онбординг в SE 3.0 частью системы: разработай небольшой гайд для новых сотрудников, как у вас используются
ИИ-инструменты, какие стандарты, покажи им вашу библиотеку промптов, policy и тд. Проводи воркшопы, делись успехами и провалами пилотов. Чтобы знания не остались точечными, а распространились по организации
Для компании / бизнеса (план для уровня орг-стратегии)
30 дней
- проведи класификацию данных и определи, что категорически нельзя допускать в открытые ИИ-сервисы: например, исходники, содержащие персональные данные, или коммерческую тайну, или чувствительные модели данных. Выпусти приказ/политику, доведи до всех команд. Это чтобы снизить риск утечек
- определи допустимые контуры инфраструктуры: где готовы использовать внешние облака, а где только
on-prem. Минимальные требования аудита при этом: например, что все запросы к внешнему API логируются, или что перед использованием нового сервиса надо пройти security-ревью - выдели 2–3 "безопасные зоны ROI" – области, где
AIскорее всего быстро окупится. Как уже упоминал: генерация тестов, документации, обновление библиотек, поддержка техподдержки (какие-то GPT-чаты для ответа на вопросы), ускорение triage. Сфокусируй на них усилия пилотных команд - назначь владельца политики AI (кто в компании отвечает за обновление правил и их соблюдение) и владельца метрик качества (Chief Engineer или Head of QA, кто будет следить за дефектами, CFR и тп. в динамике). Чтобы был конкретный ответственный человек за эти направления
90 дней
- запусти хотя бы один корпоративный пилот-проект по
AI-интеграции, обязательно с контролем метрик и контрольной группой. Т.е. выбери, например, две схожие команды: одну оснащаемAI-инструментами, другую нет, и через 2-3 месяца сравни их показатели. Такой эксперимент даст ценные данные, действительно ли в ваших условиях есть эффект - сформируй единые quality gates и стандарты CI/CD для всей организации: минимальный необходимый набор (например, "ни один сервис не деплоится без 80% юнит-тест покрытия и прохода через Static Code Analysis"). Задекларируй это и отслеживай, как внедряется.
AIили нет – но базовые гигиенические нормы должны быть везде, иначе не понять, где ошибки от людей, а где от моделей - определи guardrails для агентов: на уровне компании реши, какие ограничения всегда должны применяться. Например: "ни один
AI-агент не имеет права напрямую писать в prod-ветку, только через PR"; "агенты не получают доступ к прод-данным"; "лимит изменений от агента – не более 100500 файлов за раз" и тд Это должно быть встроено в инструменты (policy-as-code) и понятно всем - начни платформенную стандартизацию: если есть платформа (внутренний PaaS), включи
AI-помощники в ее роадмап. Если нет – возможно, задумайся над созданием общей инфраструктуры: например, внутреннего "кодового ассистента", который знает ваш код и интегрирован с корпоративной базой знаний. Через 3 месяца хотя бы план и оценку сделай
365 дней
- построй внутренний "AI as a Service" – грубо говоря, корпоративный аналог
ChatGPT, заточенный под ваши данные и процессы. Это оправдано, если у вас достаточно большой масштаб (сотни разработчиков). Так ты снизишь зависимость от внешних моделей, плюс сохранишь знания внутри - интегрируй безопасность и комплаенс в конвейер разработки. В идеале, через год вся проверка безопасности (статический анализ, проверки лицензий, compliance чеклисты) должна быть такой же частью CI, как сборка. Никаких "ручных фаз после релиза". И для AI-кода – те же требования
- пересобери организационную модель вокруг нового подхода: возможно, пересмотреть структуру команд (меньше ли они теперь? или нужны новые роли), отчетность (как часто и что доносить до менеджмента о состоянии дел?), схемы найма (каких людей ищем – может, больше системных инженеров, меньше джунов?). То есть, адаптируй оргструктуру к тому, что меняется характер труда
- сделай культуру качества измеримой: добейся, чтобы любые инициативы (в том числе
AI-внедрения) отражались в метриках CFR, MTTR, defect rates. Если что-то "улучшаешь", то видеть это цифрами. За год реально поставить сбор этих данных и научиться показывать руководству прогресс не презентациями, а объективно
Если хочешь выиграть в эпоху SE 3.0, тебе нужна не "самая умная модель", а умный конвейер. То есть, идеально отлаженная связка: намерение -> генерация -> проверка -> поставка -> наблюдение -> обратная связь. Организация, умеющая учиться и улучшать этот цикл, обойдет любую, которая просто купила мощный ИИ, но не изменилась сама
Заключение
ИИ в разработке - это новый скачок абстракции, который делает дешевле и быстрее создание черновых артефактов (кода, тестов, конфигов, документации), но дороже всё, что связано с ответственностью: проверкой качества, безопасностью, эксплуатацией и управлением рисками. В некотором смысле, работа разработчика становится сложнее, а не проще – но и интереснее: рутины меньше, больше архитектурных и творческих задач. Чем точно ИИ не является - это "концом профессии или волшебной кнопкой
Если собрать всю статью в одну формулу, получится: скорость стала дешёвой, качество стало стратегией
Что было-бы полезно запомнить
- ИИ усиливает сильные команды и вскрывает слабые. Если у вас уже есть культура дисциплины (спеки, тесты, ревью, метрики, мониторинг), AI-инструменты дадут вам огромный буст – вы быстро вырветесь вперед. Если же у вас хаос, то ускорение через
ИИпросто быстрее этот хаос проявит
Технологии × культура = результат
- главное бутылочное горлышко смещается в верификацию. Теперь узкое место – не написать код, а проверить его как следует. Чтобы выпускать больше изменений безопасно, нужно проверять быстрее и умнее. Автотесты, статические анализаторы, мониторинг – вот куда надо вкладываться больше, чем раньше
- "микрокоманды" возможны, но не сами по себе. Да,
ИИ-ассистенты теоретически позволяют 2–3 инженерам делать работу целого отдела. Но это реально только когда значительная часть функций закрыта платформой и конвейером: есть golden paths, policy-as-code, quality gates, observability. Без этого попытка работать маленькой командой на большом продукте обречена
- VibeCoding – отличный способ быстро двигаться, но без guardrails это дрифт в неизвестность. Писать код в диалоге с
ИИ, не делая пауз на документацию или тесты, – заманчиво. Но каждый такой шаг без контроля увеличивает технический долг и риски. Поэтому пользуйся vibe-coding для прототипов и творческого ресерча, но продуктовый код обкладывайте ограничениями и проверками
Искусственный интеллект уже становится частью повседневной разработки. Наша задача – сделать так, чтобы он стал не игрушкой и не угрозой, а надежным ускорителем, подконтрольным и полезным. Software Engineering 3.0 – это симбиоз человека и машины, где сильные стороны каждого дают суммарно больший результат
Задавай правильные намерения, строй процессы и культуру, не бойся мерить правду о своей работе – и тогда никакой AI тебе не страшен, наоборот, ты извлечешь из него максимум. Впереди интересное десятилетие, в котором именно сочетание инженерного мышления + возможности ИИ определит, какие продукты и команды взлетят, а какие останутся позади
Пусть твоя команда будет в числе первых
Примечания
В данном разделе находится ряд информационных блоков которые помогут усилить знание контекста и которые не хотелось выносить отдельно, спекулируя объёмом собранного материала. Также мне не хотелось вставлять это в текст, чтобы мы не уходили в рекурсию и возвращались забыв нить повествования
Ниже я расскажу
- выжимку из одной статьи по исследованиям
Microsoft - несколько блоков про Agen Experience (аналог UX и DX но в рамках "нового" домена)
- секция про управление
- и про микрокоманды
Что меняется по ролям - summary по "Working with AI: Measuring the Applicability of Generative AI to Occupations"
Исследование "Working with AI: Measuring the Applicability of Generative AI to Occupations" предлагает практический способ говорить об "автоматизации профессий" без лозунгов. Вместо бинарного "заменит/не заменит" авторы измеряют применимость генеративного ИИ к разным видам работ через структуру задач: где результат хорошо формализуется, разбивается на шаги и проверяем (через тесты, критерии, правила, сравнение с источниками), там потенциал усиления выше. Там же, где работа завязана на неопределённость, ответственность, конфликт целей, контекст организации и необходимость принимать решения под риском, ИИ скорее меняет форму труда, чем "заменяет исполнителя". Для разработки ПО это означает сдвиг: растёт доля AI-генерируемых артефактов, но ценность человека смещается в постановку намерения, формулирование критериев корректности, верификацию, безопасность и владение последствиями — то есть ровно в те слои, которые в статье обозначены как SE 3.0
Топ-40 профессий с самой высокой применимостью GenAI (это не "заменят", а "есть заметная доля задач, где ИИ уже применим")
- Interpreters and Translators — переводчики (устные и письменные)
- Historians — историки
- Passenger Attendants — сопровождающие/стюарды для пассажиров (на транспорте)
- Sales Representatives of Services — менеджеры по продажам услуг
- Writers and Authors — писатели, авторы текстов
- Customer Service Representatives — специалисты поддержки/контакт-центра
- CNC Tool Programmers — программисты ЧПУ (программы для станков/оборудования)
- Telephone Operators — телефонисты/операторы телефонной связи
- Ticket Agents and Travel Clerks — кассиры/агенты по билетам и тревел-клерки
- Broadcast Announcers and Radio DJs — дикторы/ведущие эфира и радиодиджеи
- Brokerage Clerks — клерки/операционисты в брокерских операциях
- Farm and Home Management Educators — преподаватели/консультанты по ведению фермы и домашней экономике
- Telemarketers — телемаркетологи (продажи/опросы по телефону)
- Concierges — консьержи
- Political Scientists — политологи
- News Analysts, Reporters, Journalists — новостные аналитики, репортёры, журналисты
- Mathematicians — математики
- Technical Writers — технические писатели
- Proofreaders and Copy Markers — корректоры/вычитчики (в т.ч. разметка правок)
- Hosts and Hostesses — хосты/хостес (встреча гостей, посадка и т.п.)
- Editors — редакторы
- Business Teachers, Postsecondary — преподаватели бизнеса (вуз/послевуз)
- Public Relations Specialists — PR-специалисты
- Demonstrators and Product Promoters — промоутеры/демонстраторы товара
- Advertising Sales Agents — менеджеры по продаже рекламы
- New Accounts Clerks — клерки по открытию новых счетов/аккаунтов (банк/брокер/сервисы)
- Statistical Assistants — помощники статистиков
- Counter and Rental Clerks — сотрудники стойки (прокат/выдача/оформление аренды)
- Data Scientists — дата-сайентисты
- Personal Financial Advisors — персональные финансовые консультанты
- Archivists — архивисты
- Economics Teachers, Postsecondary — преподаватели экономики (вуз/послевуз)
- Web Developers — веб-разработчики
- Management Analysts — управленческие аналитики/консультанты по менеджменту
- Geographers — географы
- Models — модели
- Market Research Analysts — аналитики маркетинговых исследований
- Public Safety Telecommunicators — диспетчеры экстренных служб (типа 911/112)
- Switchboard Operators — операторы коммутатора/телефонной станции
- Library Science Teachers, Postsecondary — преподаватели библиотечного дела (вуз/послевуз)
Низ-40 профессий с самой низкой применимостью GenAI (в основном — физический труд, работа руками/с оборудованием/с людьми "вживую")
- Phlebotomists — флеботомисты (забор крови)
- Nursing Assistants — помощники медсестры/санитары (уход)
- Hazardous Materials Removal Workers — специалисты по удалению опасных материалов
- Helpers–Painters, Plasterers, … — подсобные рабочие у маляров/штукатуров и смежных
- Embalmers — бальзамировщики
- Plant and System Operators, All Other — операторы установок/систем (прочие)
- Oral and Maxillofacial Surgeons — челюстно-лицевые хирурги
- Automotive Glass Installers and Repairers — установщики/ремонтники автостёкол
- Ship Engineers — судовые инженеры/механики
- Tire Repairers and Changers — ремонт/замена шин
- Prosthodontists — стоматологи-ортопеды (протезирование)
- Helpers–Production Workers — подсобные рабочие на производстве
- Highway Maintenance Workers — дорожные рабочие (обслуживание трасс)
- Medical Equipment Preparers — подготовка медоборудования (стерилизация/комплектация)
- Packaging and Filling Machine Op. — операторы фасовочно-упаковочных машин
- Machine Feeders and Offbearers — податчики/съёмщики заготовок у станков
- Dishwashers — посудомойщики
- Cement Masons and Concrete Finishers — бетонщики/отделочники бетона
- Supervisors of Firefighters — руководители/начальники пожарных подразделений
- Industrial Truck and Tractor Operators — водители погрузчиков/промышленных тягачей
- Ophthalmic Medical Technicians — офтальмологические медтехники
- Massage Therapists — массажисты
- Surgical Assistants — ассистенты хирурга
- Tire Builders — сборщики шин (производство)
- Helpers–Roofers — подсобные у кровельщиков
- Gas Compressor and Gas Pumping Station Op. — операторы газокомпрессорных/перекачивающих станций
- Roofers — кровельщики
- Roustabouts, Oil and Gas — разнорабочие/риггеры в нефтегазе
- Maids and Housekeeping Cleaners — горничные/уборщики
- Paving, Surfacing, and Tamping Equipment Op. — операторы дорожной техники (укладка/трамбовка)
- Logging Equipment Operators — операторы лесозаготовительной техники
- Motorboat Operators — операторы моторных лодок/катеров
- Orderlies — санитар(к)и (медучреждения)
- Floor Sanders and Finishers — шлифовщики/отделочники полов
- Pile Driver Operators — операторы сваебойных установок
- Rail-Track Laying and Maintenance Equip. Op. — операторы техники по укладке/обслуживанию ж/д путей
- Foundry Mold and Coremakers — формовщики/стерженщики (литейное производство)
- Water Treatment Plant and System Op. — операторы водоочистных сооружений/систем
- Bridge and Lock Tenders — смотрители мостов и шлюзов
- Dredge Operators — операторы земснаряда (дноуглубление)
Источник: Working with AI: Measuring the Applicability of Generative AI to Occupations
Но и это ещё не всё, данная статья была "подарена" мне моим коллегой Владиславом Павловым и она удачно легла в контекст моего размышления о ролях будущего. Ниже приведена схема о которой я много дискутировал и над которой много размышлял в течении прошлого года. Мне кажется, что это потенциально рабочая визуализация трансформации ролей на ближайшее будущее. Для меня примечательно то, что здравый смысл и наблюдения показывают как разделение труда может развернуть свою рекурсию назад и начать сокращать количество профессий за счёт хорошего инструмента. Да - это происходит в истории не впервые, но на моём веку это одна из самых яркив трансформаций
Легенда
- классические роли — белая рамка
- AI-роли — красная рамка
- стрелки "перехода" — красные
- стрелки "частичного пересечения" — белые пунктиром (двойной смысл). Пересечения с новой ролью есть, но "старая" роль не распадается
Agent Experience (AX): DevEx для агентов
Если DevEx отвечает за удобство и эффективность человека в процессе поставки, то при переходе к AI-driven появляется новый слой — AX (Agent Experience): удобство, предсказуемость и управляемость агентов
AX — про то в каких условиях агент работает и если его среда не спроектирована, ускорение быстро превращается в хаос.
AX включает:
Контекст
- какие данные агент видит
- какие репозитории, сервисы и артефакты доступны
- где границы (что принципиально запрещено)
Права и ответственность
- что агент может читать / менять / выполнять
- какие действия требуют human approval
- кто владелец риска за результат
Интерфейсы и контракты
- через какие
APIи инструменты агент действует - какие форматы входа / выхода считаются допустимыми
- как агент встраивается в
golden pathsплатформы
Трассировка и аудит
- что агент сделал, когда и почему
- какие источники использовал
- какие гипотезы и варианты рассматривал
Контуры остановки и эскалации
- когда агент обязан остановиться
- когда передать решение человеку
- как обрабатывается неопределённость
Без AX агентность
- ускоряет выпуск изменений
- но снижает объяснимость
- увеличивает риск регрессий
- усложняет аудит и расследования
С AX агентность становится индустриальной - быстро, повторяемо, проверяемо и безопасно. По сути, AX — это DevEx + Security + Observability, но применённые не к человеку, а к агенту.
DX vs AX: DevEx для людей и Agent Experience для агентов
| Измерение | DX (Developer Experience) | AX (Agent Experience) |
|---|---|---|
| Объект "опыта" | Человек-разработчик | AI-агент (автономный/полуавтономный) |
| Цель | Сделать разработку быстрее, качественнее и менее фрустрирующей | Сделать действия агентов предсказуемыми, управляемыми и безопасными |
| Главный вопрос | "Как инженеру удобно и эффективно поставлять изменения?" | "Как агенту безопасно и воспроизводимо производить артефакты под контролем?" |
| Типичные артефакты | шаблоны проектов, docs, SDK, CLI, внутренние библиотеки, onboarding-гайды | policy-as-code, профили прав, контрактные интерфейсы инструментов, guardrails, runbooks для агентов |
| Контекст | документация, код-база, примеры, "golden path" | RAG/репо-контекст, разрешённые источники, границы контекста, "зоны запрета" |
| Права и доступы | доступы инженера к системам (репо, CI, облако) | минимально необходимые права агента, sandbox, allowlist действий/директорий |
| Quality gates | линтеры, тесты, статанализ, ревью | те же гейты + обязательные stop-conditions + запрет небезопасных классов изменений |
| Наблюдаемость | метрики DORA/SPACE, трассы CI, логирование релизов | полная трасса действий агента: какие шаги, какие инструменты, какие источники, почему так |
| Аудит и комплаенс | аудит релизов и доступов человека | аудит "decision trail" агента + подпись/происхождение артефактов (SBOM/SLSA) |
| Основные риски | фрикция, потеря времени, рост текучки, "сделали обходной путь" | "работает, но никто не понимает почему", скрытые уязвимости, неконтролируемые изменения, дрейф поведения |
| Ключевые меры | стандартизация, self-service платформа, docs, автоматизация рутины | ограничение автономности, guardrails, политика контекста, воспроизводимость, human approval |
| Типичный "провал" | "У нас есть инструменты, но ими неудобно пользоваться" | "У нас есть агенты, но мы не понимаем, что они делают и как это контролировать" |
| Итоговая формула | DX = скорость + удобство + ясность | AX = автономность + контроль + доказуемость |
Управление и культура качества: почему менеджмент тоже меняется

ИИ увеличивает скорость выпуска изменений. Значит, менеджмент должен перестроиться вокруг двух осей
- управление риском (чтобы скорость не превращалась в аварии)
- управление качеством конвейера (чтобы изменения были проверяемыми)
В эпоху ИИ выигрывает та, у которой быстрее и надёжнее работает контур верификации
Минимальный набор метрик (чтобы не спорить "стало лучше/хуже"). Можно взять базовые DORA-метрики (Four Keys) + качество
- Lead time (время от идеи/PR до продакшена)
- Deployment frequency (частота поставок)
- Change failure rate (CFR) (доля изменений, приводящих к инцидентам/откатам)
- MTTR (время восстановления)
- Defect escape rate (дефекты, ушедшие в прод)
- Flaky rate (нестабильные тесты)
- Security findings rate (уязвимости/секреты/комплаенс нарушения)
Если после внедрения ИИ lead time падает, а CFR растёт — ты не ускорился, ты взял кредит у будущего
Микрокоманды и "перенос производства" на меньший состав

В разговорах про "команды по 1–3 человека" часто путают две вещи
- производство кода (его действительно можно сильно ускорить)
- производство продукта (где есть безопасность, качество, поставка, интеграции, поддержка)
ИИ реально позволяет уменьшить количество людей в контуре производства — но только если часть функций переносится
- в платформу (golden paths, шаблоны, инфраструктура, политики)
- в автоматическую верификацию (тесты, сканеры, quality gates)
- в ИИ-автоматизацию рутины (агенты и ассистенты)
Микрокоманда возможна потому что система берёт на себя часть функций, которые раньше делали люди
Три профиля продукта и разные "минимальные составы"
Ниже — не "прописная истина", а модель: как рассуждать о минимальном составе
| Тип продукта | Минимальный состав без платформы | Минимальный состав с платформой + ИИ | Что ИИ берёт на себя | Что остаётся людям |
|---|---|---|---|---|
| MVP/стартап (низкий комплаенс, быстрые итерации) | 3–6 | 1–3 | быстрые прототипы, черновой код, тест-обвязка, документация | продуктовые решения, UX-смысл, архитектурные рамки, финальная проверка |
| Продукт в росте (качество и скорость важны одинаково) | 8–15 | 4–8 | миграции, рутину, тесты, triage, автоматизацию проверок | архитектура, надёжность, масштабирование, производительность, SLO |
| Энтерпрайз/критичный домен (безопасность/регуляторика) | 15–50+ | 10–30+ | стандартизация, генерация типовых частей, ускорение анализа/ревью/доков | контуры безопасности, комплаенс, интеграции, audit, ответственность |
Потому что производство — это не только код. Это ещё
- безопасная поставка (supply chain)
- соответствие политикам
- интеграции с десятками систем
- наблюдаемость и эксплуатация
- регуляторика
ИИ сокращает часть работы, но не отменяет необходимость этих функций
Модель "минимальной команды" по функциям (не по должностям)
Вместо "сколько человек" полезнее думать "какие функции должны быть закрыты"
- Product intent (что строим и зачем)
- Domain modeling (что является инвариантами и правилами домена)
- Implementation (код, инфраструктура, интеграции)
- Verification (тесты, ревью, безопасность, качество)
- Delivery/Operations (релиз, наблюдаемость, поддержка)
ИИ помогает в implementation и частично в verification, но
- domain modeling и ответственность остаются за людьми
verificationдолжен быть усилен системой (gates), иначе скорость превращается в хаос
Типовые рычаги для уменьшения состава без потери качества
- Golden paths (шаблоны сервисов/приложений)
- один раз сделали правильно -> сотни раз используем
- Policy-as-code
- правила (security/compliance/архитектура) выполняются автоматически
- Стандартизированная наблюдаемость
- логирование/метрики/трейсы "из коробки"
- Авто-верификация
- тестовые пайплайны и проверки, которые невозможно "обойти случайно"
- ИИ-автоматизация рутины
- агенты для миграций, обновлений, генерации тестов, triage
Микрокоманды рождаются там, где "платформа + гейты + ИИ" превращают хаос в конвейер
Источники
Академические: методология исследования (SLR/MLR/Mapping)
- Towards AI-Native Software Engineering (SE 3.0): A Vision and a Challenge Roadmap
- Kitchenham, B., Charters, S. — Guidelines for performing Systematic Literature Reviews in Software Engineering (2007)
- PRISMA 2020 — сайт стандарта
- PRISMA 2020 — статья в BMJ (Page et al., 2021)
- Wohlin, C. — Guidelines for Snowballing in Systematic Literature Studies and a Replication in Software Engineering (EASE 2014)
- Garousi, V. et al. — Guidelines for including grey literature and conducting multivocal literature reviews in software engineering (arXiv)
- Cochrane Handbook for Systematic Reviews of Interventions
Академические: фундамент LLM/агентов (база для "как это работает")
- Vaswani et al. — Attention Is All You Need (Transformer) (arXiv:1706.03762)
- Brown et al. — Language Models are Few-Shot Learners (GPT‑3) (arXiv:2005.14165)
- Ouyang et al. — Training language models to follow instructions with human feedback (InstructGPT) (arXiv)
- Wei et al. — Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (arXiv:2201.11903)
- Schick et al. — Toolformer: Language Models Can Teach Themselves to Use Tools (arXiv)
- Yao et al. — ReAct: Synergizing Reasoning and Acting in Language Models (arXiv)
- Minaee et al. — Large Language Models: A Survey (arXiv:2402.06196)
Академические: LLM в Software Engineering (обзоры/дорожные карты)
- Hou et al. — Large Language Models for Software Engineering: A Systematic Literature Review (ACM TOSEM, 2024)
- Hou et al. — PDF версии обзора (TOSEM 2024)
- Zhang et al. — A Survey on Large Language Models for Software Engineering (arXiv:2312.15223)
- Liu et al. — Large Language Model-Based Agents for Software Engineering (arXiv:2409.02977)
- Hassan et al. — Agentic Software Engineering: Foundational Pillars and a Research Roadmap (arXiv:2509.06216)
- iSEngLab — AwesomeLLM4SE (живой репозиторий ссылок)
- arXiv:2507.07935 — статья, которую ты разбирал ранее
Бенчмарки и датасеты для "AI‑помощников" в кодинге и SDLC
- Chen et al. — Evaluating Large Language Models Trained on Code (HumanEval / Codex) (arXiv)
- Austin et al. — Program Synthesis with Large Language Models (MBPP) (arXiv)
- Lu et al. — CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation (arXiv)
- SWE‑bench — Can Language Models Resolve Real‑World GitHub Issues? (GitHub)
Software Engineering: классика (чтобы показать "как мы пришли сюда")
- Royce, W. — Managing the Development of Large Software Systems (1970) (PDF)
- Manifesto for Agile Software Development
- Brooks, F. — No Silver Bullet: Essence and Accidents of Software Engineering (PDF)
- Humble, J., Farley, D. — Continuous Delivery (сайт книги)
- Forsgren, Humble, Kim — Accelerate (книга)
Метрики продуктивности / DevEx / DORA
- Forsgren, Storey, Maddila et al. — The SPACE of Developer Productivity (ACM Queue / DOI)
- DORA — официальный сайт
- Google Cloud — Four Keys (метрики DORA)
Индустриальные отчёты и опросы (рынок, профессии, тренды)
- Stanford HAI — AI Index Report 2025 (страница)
- Stanford HAI — AI Index Report 2025 (PDF)
- GitHub — Octoverse 2025
- Stack Overflow — Developer Survey 2025
- Microsoft & LinkedIn — Work Trend Index 2024 (Report)
- DORA — State of DevOps Report 2024 (Google Cloud)
- McKinsey — The economic potential of generative AI (2023)
- World Economic Forum — The Future of Jobs Report 2025
Регулирование, безопасность, supply chain (важно для "энтерпрайза")
- EU AI Act — Regulation (EU) 2024/1689 (Eur‑Lex, HTML)
- EU AI Act — Regulation (EU) 2024/1689 (Eur‑Lex, PDF)
- NIST — AI Risk Management Framework (AI RMF 1.0) (PDF)
- NIST — AI RMF Playbook
- NIST — Secure Software Development Framework (SSDF) SP 800‑218 (PDF)
- NIST — Secure Software Development Framework (SSDF) (страница публикации)
- NIST — Generative AI Profile к AI RMF (NIST AI 600‑1) (PDF)
- OWASP — Top 10:2021 (официальная страница)
- SLSA — спецификация v1.2
- Sigstore — Cosign docs
- SPDX 3.0 — спецификация (OMG)
- in-toto — спецификации
- in-toto — Attestation Framework (GitHub)
Документация платформ/инструментов (практический слой)
LLM API / облака
- OpenAI — API docs (Platform)
- OpenAI — API reference
- Anthropic — Documentation
- Anthropic — Tool use
- Microsoft — Azure OpenAI REST API reference
- Google — Vertex AI function calling
- AWS — Amazon Bedrock Agents (User Guide)
Инструменты для разработчиков / агентные фреймворки
- GitHub — Copilot (Get started)
- LangChain — Documentation
- LangChain — Introduction (Python)
- LangChain — Introduction (JS)
- LangGraph — Quickstart
- LlamaIndex — Documentation (Home)
- LlamaIndex — High-Level Concepts
РФ / локальные платформы
- Сбер — GigaChat API (документация на developers.sber.ru)
- Указ Президента РФ №490 (Нац. стратегия развития ИИ до 2030)
- ВШЭ (ИСИЭЗ) — материалы по ИИ в РФ (поиск на странице)